![Imagen ornamental, basada en una ilustración gratuita de Veronica Baranova en mixkit.co/@veronicabaranova)]()
Empecemos con un breve repaso a los formatos de imágenes de mapas de bits para la Web existentes hasta ahora ya que nos ayudara a entender las virtudes y defectos del nuevo formato...
Los formatos tradicionales de imágenes para la web, GIF, JPG y PNG han logrado estar de plena vigencia durante décadas. Cada uno de ellos tiene sus propios pros y contras, usos apropiados y limitaciones, pero entre los tres logramos gestionar bien las necesidades de imágenes de nuestros sitios y aplicaciones web.
En septiembre de 2010 Google lanzó el formato de imagen WebP. Se basa en el formato de vídeo VP8 y es hermano del formato de contenedor de vídeo WebM, también de Google y lanzado unos pocos meses antes. WebP soporta lo mejor de todos los demás formatos: compresión sin pérdida (y con pérdida si queremos más compresión) y transparencias como PNG, secuencias de imágenes para animaciones como GIF y un peso reducido como JPG. De hecho, las imágenes en WebP suelen pesar sustancialmente menos que las imágenes JPG, para ofrecer la misma calidad.
De todos modos, WebP presenta varios problemas. Está limitado al uso de tan solo 8 bits para la profundidad de color, y usa submuestreo de crominancia que almacena el color a la mitad de la resolución de la imagen, lo cual está bien para vídeo pero no para imágenes estáticas. Además, el resto de los navegadores tardaron demasiado en dar soporte al formato. Firefox empezó a soportarlo en su versión 65 en enero de 2019 (¡9 años después!) y Safari tan solo ha empezado a soportarlo desde septiembre de 2020 con su versión 14, exclusivamente en macOS "Big Sur". O sea, hace nada.
Por lo que, en la práctica, no puedes usar tan solo WebP y garantizar que se vean tus imágenes en todos los navegadores, como sí ocurre con los formatos tradicionales.
El nuevo formato AVIF
AVIF es el acrónimo de AV1 Image File Format y es un nuevo formato de imagen de bits para la Web, de libre uso, creado por la Alliance for Open Media (AOMedia), una organización en la que están todas las grandes organizaciones con intereses en Internet y en especial en el mundo multimedia, como Google, Netflix, Vimeo, Microsoft, Intel, Amazon, Apple, Facebook, NVidia y muchas más.
Al igual que WebP, AVIF es un formato que se basa en un códec de vídeo. En concreto es la combinación del estándar ISO HEIF (High Efficiency Image File Format) para el contenedor, y el codec de vídeo AV1, open source y libre de derechos, desarrollado por AOMEdia.
Dicho de manera básica, al igual que WebP, una imagen AVIF es un frame de un vídeo en un contenedor de imagen para darle soporte de metadatos y otras cuestiones. La principal diferencia es que WebP utiliza el codec VP8, mientras que AVIF usa el mucho más moderno y potente AV1, que, como sabemos, además es libre y de código abierto.
El uso de este codec ofrece varias mejoras frente a VP8, entre ellas un sustancial menor tamaño para la misma calidad de la imagen (más sobre esto ahora) y el soporte para imágenes de alto rango dinámico (HDR), ofreciendo mayor gama y profundidad de colores y más brillo.
Al igual que WebP, soporta imágenes con o sin pérdida, transparencia y animaciones.
¿Menor tamaño en imágenes AVIF?
En la mayor parte de los sitios verás que se hace hincapié en la reducción de peso que tienen las imágenes AVIF respecto a los demás formatos, incluso frente a WebP que era el campeón en esto. Y es cierto: para una misma calidad de la imagen se pueden conseguir reducciones de "peso" de hasta el 50% frente a JPG sin perder calidad apreciable. Frente a WebP las ganancias no son tan grandes (andan en torno al 20%), pero si manejas muchas imágenes (como Netflix), sin duda es un factor que marca la diferencia.
Pero otro modo de verlo, quizá más adecuado, es al contrario: si dejamos fijo el tamaño de la imagen en varios formatos ¿qué diferencias observamos?
Y digo esto porque, en realidad, es posible conseguir casi cualquier tamaño de imagen con cualquier formato con pérdidas como JPG o WebP. Lo verdaderamente importante es ver la relación entre el tamaño y la calidad visual que conseguimos. Si yo le digo a un codificador JPG que preserve pocos detalles puede comprimir muchísimo la imagen. Y al revés: si le digo a un codificador WebP o AVIF que conserve mucho la definición de la imagen poco podrá hacer para reducir el tamaño.
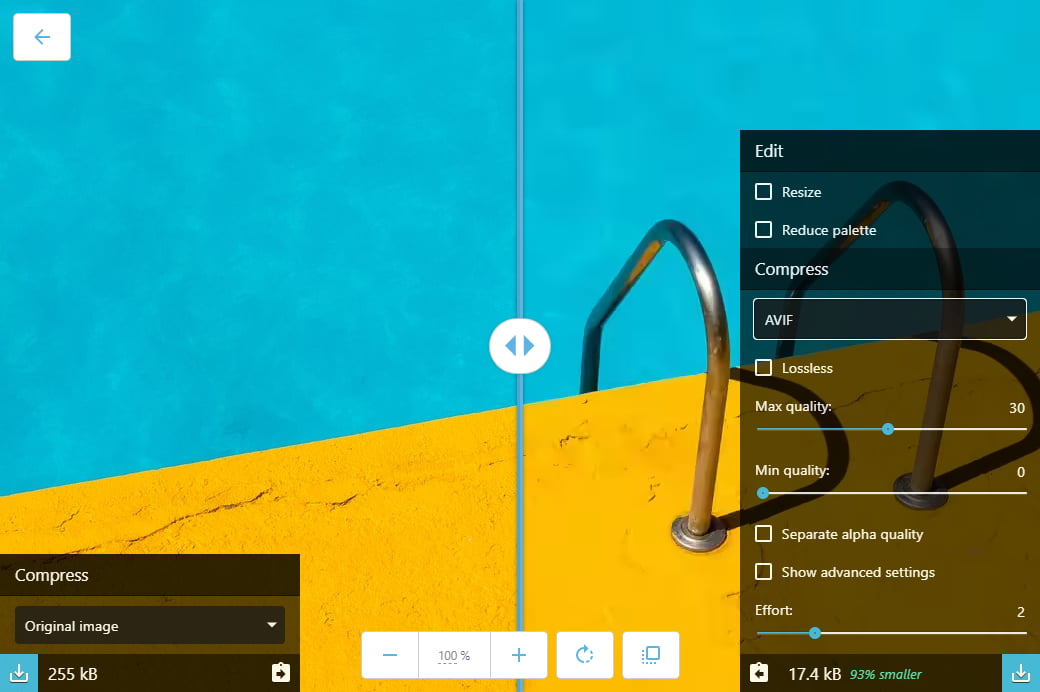
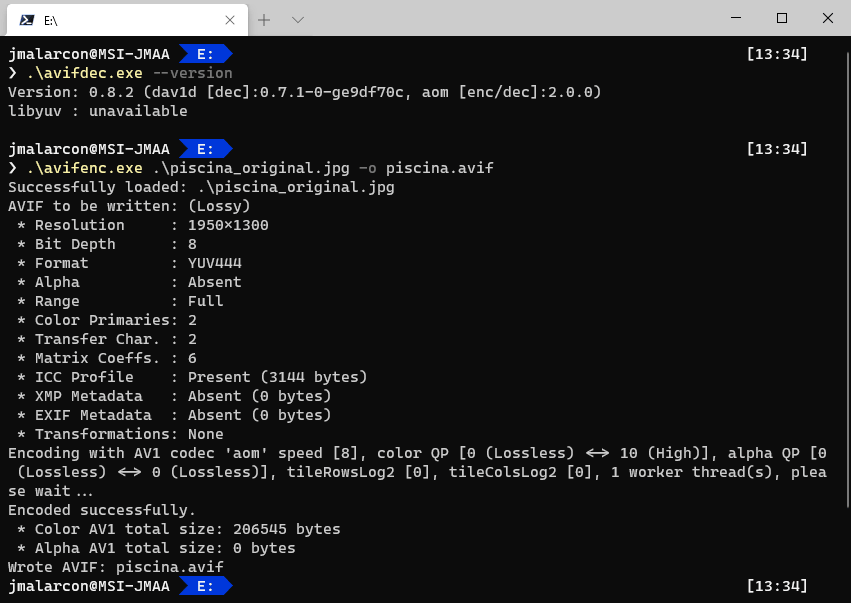
Y en este tipo de comparación AVIF lleva también la delantera. Una forma muy sencilla de comprobarlo es comprimir la misma imagen en 3 formatos con pérdidas. Por ejemplo, he tomado esta imagen de una piscina del fotógrafo Etienne Girardet, que he descargado en tamaño mediano y tiene unas dimensiones de 1950x1300, o sea, un poquito más que Full-HD, y pesa 250KB en formato JPG con poca compresión. La he convertido a AVIF, WebP y JPG consiguiendo que pese en los 3 casos tan solo 17KB. Es decir, más o menos puedes lograr el tamaño que quieras, como ves muy reducido.
Te las dejo aquí en un ZIP (400KB) para que puedas compararlas (ábrelas en Chrome), pero en la siguiente figura te dejo un detalle (sin aumentar, tamaño real) de la misma parte de la fotografía en los 4 casos: original y en los tres formatos pesando muy poco:
![Comparación de detalle de las imágenes, a igual peso, con la original]()
Como se hace evidente, a mismo tamaño AVIF ofrece una definición mucho mayor que los otros dos formatos, aunque pierde calidad sustancialmente frente a la original. Se nota sobre todo en la definición: tanto en la rugosidad del suelo, que casi desaparece, como en la barra de la escalera que se alisa mucho, o el borde de la piscina, que se ve mucho menos nítido. Pero claro, es que pesa menos del 8% que la original, y no se pierde tanto. Especialmente si la imagen es pequeña.
Ahora bien, para conseguir un nivel de nitidez muy similar al de la imagen original, hay que jugar mucho con los posibles ajustes y lo logras con aproximadamente la mitad de peso, para ser exactos un 56% menos, y solo 108KB (la tienes en el ZIP también). Ahí, yo al menos, no noto apenas diferencias. Lo que es un logro estupendo.
Pero al final, lo interesante es que, según la imagen, sus dimensiones y la definición que necesitemos con AVIF podremos conseguir siempre grandes mejoras de peso para esos mismos parámetros comparado con los otros formatos.
Luego veremos, de todos modos, que no todo son alegrías y también hay algunas pegas...
Cómo podemos crear imágenes en formato AVIF
La manera más sencilla de todas, apropiada para trabajar con imágenes individuales, es la fantástica herramienta Squoosh de Google Chrome Labs. Esta app (se puede instalar como PWA) te permite arrastrar o cargar una imagen y convertirla a diferentes formatos usando varias técnicas diferentes y con capacidad para ajustar un montón de parámetros. Además, te muestra la versión original de la fotografía junto a la transformada para que puedas compararlas con una barra deslizante:
![La interfaz de usuario de Squoosh]()
Esta herramienta soporta AVIF y es muy interesante para optimizar una imagen antes de subirla a la Web.
En Windows 10 (versión posterior a la de mayo de 2019) tenemos soporte nativo del formato instalando la extensión AVIF desde la tienda de Windows. Esto nos permite no sólo tener vistas previas de las imágenes en el explorador de Windows, sino que la imagen esté soportada por editores gráficos como Paint, el programa sencillo de edición gráfica que viene con Windows, o mi favorito que uso todo el rato: Paint.net, por lo que podrás usarlo para generar las imágenes en este formato, controlando los parámetros para ello.
Todo esto está muy bien para manejar unas pocas imágenes, pero si necesitas hacer conversiones masivas debes ir por otro camino: el camino de la línea de comandos.
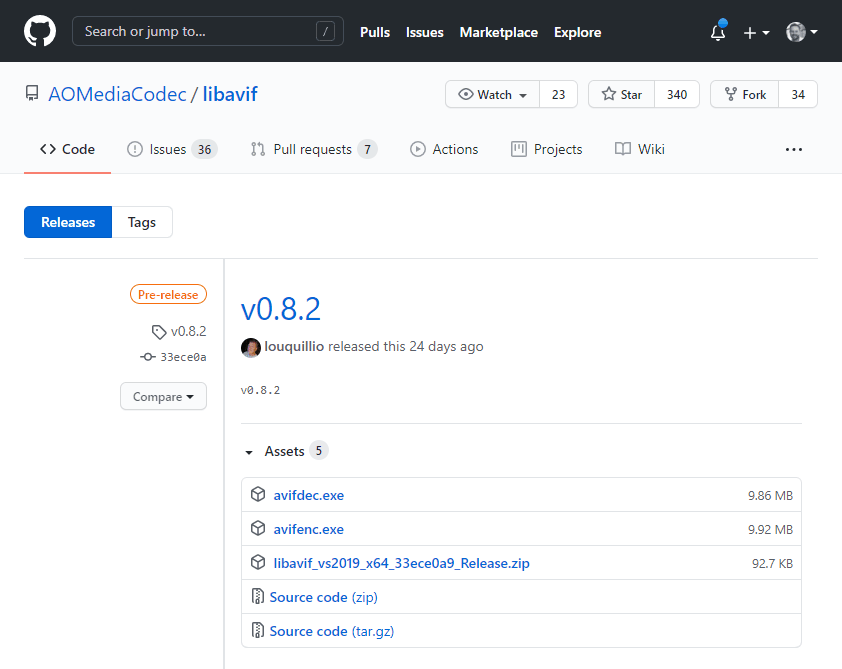
La AOMedia dispone de una implementación escrita en lenguaje C, de código abierto y multiplataforma. Si visitas las releases del proyecto en GitHub podrás encontrar la biblioteca compilada para Windows en forma de 2 ejecutables listos para usar:
![Las descargas de LIBAVIF en GitHub]()
En macOS la puedes instalar directamente desde Homebrew:
brew install joedrago/repo/avifenc
brew install joedrago/repo/avifdec
El uso básico es muy sencillo pues basta con indicar el nombre del archivo de destino con el parámetro -o (o --output) y el nombre que queremos darle al archivo:
avifenc imagenoriginal.jpg -o imagenfinal.avif
Como podemos ver en esta captura:
![Codificación en línea de comandos]()
Como ves, nos muestra los parámetros que usa por defecto e información sobre la imagen final.
Con los parámetros por defecto conseguiremos mejoras de tamaño del 50% o más respecto a un JPG sin mucha compresión. Si queremos afinar más podemos tocar muchos otros parámetros de los mostrados, usando otros tantos switch de línea de comandos. Escribe avifenc -h para ver la ayuda de cada uno de ellos.
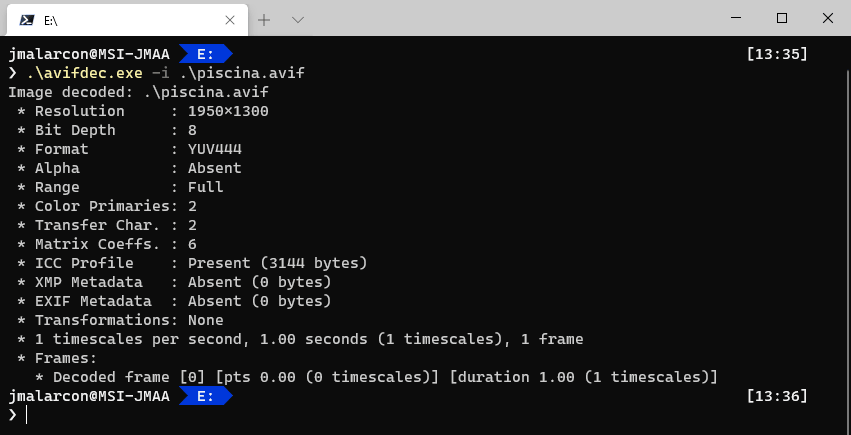
Con avifdec.exe podemos obtener información de un archivo AVIF que tengamos ya en disco, para ver qué parámetros utiliza y, si acaso, poder afinarlos con la utilidad anterior:
![El comando avifdec en acción]()
Con avifenc y un poco de maña con los scripts de línea de comandos podremos generar archivos AVIF en masa a partir de archivos JPG o PNG que tengamos.
Finalmente, algunos servicios de transformación de imágenes online en tiempo real como el que tiene Cloudflare o específicos como Cloudinary (en el momento de escribir esto lo tiene en fase experimental), ofrecen la posibilidad de generar automáticamente imágenes AVIF.
Soporte del formato AVIF en los navegadores
El formato AVIF está soportado por Chrome desde su versión 85 (finales de agosto de 2020).
En el momento de escribir esto, los demás navegadores basados en Chrome como Edge u Opera todavía no lo soportan, pero se estima que lo harán pronto. Firefox lo soporta de modo experimental (hay que ajustar el flagimage.avif.enabled en about:config), pero pronto lo tendrá de serie también.
¿Quiere decir esto que no debemos usarlo aún?
En absoluto. Chrome tiene un porcentaje brutal del mercado de navegadores porque mucha gente lo podrá visualizar ya. Para los demás puedes enviar la imagen en WebP (soportado por más todavía) o en JPG (soporte universal). Simplemente genera las tres versiones y usa la etiqueta <picture> de HTML, así:
<picture><source srcset="/imgs/miimagen.avif" type="image/avif"><source srcset="/imgs/miimagen.webp" type="image/webp"><img src="/imgs/miimagen.jpg" alt="Descripción de la foto"></picture>
Con esta etiqueta se verá la imagen AVIF si está soportada, sino se intentará la WebP y si ninguno de los dos formatos se soporta se descargará el JPG para asegurar que se ve. Dado la cuota de uso que tiene Chrome y el buen soporte de WebP que existe hoy en día, solo con esto podrás ahorrar ancho de banda y hacer que las página descarguen más rápido para tus usuarios, especialmente los de móviles, porque la mayoría descargarán la versión AVIF o WebP, y con ambas puedes ahorrar mucho peso.
Otra cuestión que es interesante conocer es que el formato AVIF ofrece muchas más posibilidades que las que disfrutamos en los navegadores hoy en día. Muchas de sus capacidades están pensadas para las cámaras de los móviles, no para la Web. Por ejemplo las fotos "live" que muestran un minivídeo previo a haber sacado la foto, las ráfagas que almacenan muchas fotos en una sola para elegir la mejor, el modo HDR para hacer doble exposición, etc...
Soporte del formato AVIF en los servidores
En el servidor es necesario hacer algún ajuste para que permita su descarga, ya que al ser un formato tan nuevo casi seguro que no tiene su tipo MIME registrado y por lo tanto no permitirá procesarlos hacia el navegador.
El tipo MIME apropiado para los archivos AVIF es image/avif.
Cómo añadir este tipo MIME va a depender del servidor que utilices, claro. En Internet Information Server, que es el servidor que me gusta y que utilizo, basta con añadir esto al archivo web.config de tu aplicación:
<system.webServer><staticContent><mimeMap fileExtension=".avif" mimeType="image/avif" /></staticContent></system.webServer>
y listo. También, claro está, lo puedes añadir globalmente al servidor para que esté soportado por todos los sitios que tengas albergados.
Desventajas de AVIF
Para terminar vamos con las malas noticias. No todo va a ser perfecto 😉
AVIF presenta dos problemas principalmente, aunque solo tienen importancia en ciertos casos:
- No soporta renderizado progresivo: es decir, al contrario que el JPG progresivo, para que el navegador pueda visualizar una imagen AVIF, primero tiene que descargarla por completo. Con los formatos progresivos es posible obtener una versión de baja resolución antes de descargar la imagen completa, mostrarla y luego seguir descargando, lo que da una sensación de carga más rápida a los usuarios. Con AVIF no es posible.
- Requiere mucha más potencia de procesador: lo habrás comprobado si has hecho pruebas de codificación con Squoosh. Codificar AVIF lleva mucho más tiempo que hacerlo en JPG, pudiendo tardar varios segundos por imagen. Más importante: decodificar AVIF también requiere más procesador que con JPG (aunque es muy rápido). No es que sea nada apreciable en un ordenador o un móvil moderno, pero en dispositivos muy antiguos sin aceleración por hardware podría ser un problema si hay muchas imágenes (o vídeo codificado con AV1). En la práctica no tendrá demasiada importancia, pero es necesario saberlo.
En resumen
En este artículo hemos dado un repaso a fondo al reciente formado de imagen AVIF. Hemos conocido los formatos que existían antes de este, cuáles son sus ventajas, cómo podemos comparar su rendimiento con el de otros formatos, cómo creamos imágenes AVIF, el soporte de navegadores y servidores y finalmente las desventajas que podríamos tener al usarlo.
Al estar detrás del formato la mayoría de las grandes empresas multimedia y de Internet, y sobre todo Google, la adopción del formato va a ser muy rápida y, como hemos visto, es fácil incluir alternativas para los dispositivos que no lo soporten.
Por todo esto es un formato muy a tener en cuenta y que deberíamos empezar a utilizar en nuestros desarrollos y sitios Web.
¡Espero que te haya resultado útil!



 Seamos realistas: para la mayoría de los desarrolladores que vienen de otros entornos, la parte más odiosa de hacer desarrollo Web es sin duda el Front-End, es decir, la interfaz de usuario. Había que decirlo y se ha dicho 😉
Seamos realistas: para la mayoría de los desarrolladores que vienen de otros entornos, la parte más odiosa de hacer desarrollo Web es sin duda el Front-End, es decir, la interfaz de usuario. Había que decirlo y se ha dicho 😉



 Ayer por la tarde a las 19:00 hora de España peninsular emitimos en directo la entrevista con nuestro tutor José María Aguilar.
Ayer por la tarde a las 19:00 hora de España peninsular emitimos en directo la entrevista con nuestro tutor José María Aguilar.

 Hace unos días tuvimos una
Hace unos días tuvimos una