Nunca ha habido un mejor momento para aprender a programar; ya desde antes de la crisis actual. Existen un gran número de cursos y plataformas de aprendizaje online, tanto gratuitos como de pago.
Para elegir un buen curso de desarrollo en una buena plataforma de formación es importante dedicar un tiempo a considerar qué curso será el mejor para ti en función del tipo de persona que eres y de tus circunstancias.
Sin una buena evaluación, puede que te encuentres a la deriva yendo de un curso a otro, en un perpetuo estado de confusión, perdiendo dinero o, lo que es más importante, tiempo (a veces un curso gratuito sale muy caro). Esto provoca frustración y puede llevar a que uno se dé por vencido y abandone la formación en esa materia por completo.
Una adecuada valoración de cada curso es fundamental para que el proceso resulte óptimo y satisfactorio. En este artículo repasaremos cinco puntos de evaluación basados en la psicología educativa, que son muy importantes a la hora de establecer un criterio para elegir un curso y una plataforma de formación online.
Sí, en el mercado hay un gran número de cursos para aprender a programar, pero al evaluarlos teniendo en cuenta estos cinco criterios, se eliminarán muchos de la lista.
Dicho esto: no todos los cursos son para todo el mundo. Dependerá de quién eres, de dónde partas en el aprendizaje, de cuáles son tus capacidades, del tiempo del que dispones, de si tienes mucha experiencia o no... No existe una "bala de plata", y una misma formación o método no tiene por qué ser válida para todo el mundo. Pero estos cinco puntos garantizan que, para la mayor parte de la gente que tiene el perfil apropiado para programar, la formación tienda a ser la más adecuada.
Vamos a verlos.
1.- El estilo de enseñanza online
No vamos a entrar aquí a repasar todos los estilos de aprendizaje, que se refieren a la forma preferida que tiene cada mente para asimilar conceptos, pero sí diremos que, la mayoría de las personas tienen un estilo dominante de aprendizaje o una combinación de estilos dominantes que son fundamentalmente estos tres:
- El aprendizaje verbal (lectura)
- El aprendizaje visual (vídeos e imágenes)
- El aprendizaje auditivo (escucha)
Esto significa que los cursos con vídeo + audio que además ofrecen material con teoría para su lectura acompañada de esquemas, imágenes y capturas, aseguran que más participantes puedan tener éxito en la realización de los mismos.
En cualquier curso de campusMVP hay contenidos verbales, visuales y auditivos, no sólo una sucesión de vídeos uno tras otro, sin pausa para reflexionar y asentar conceptos. Todos los módulos se componen de teoría para su lectura, que se refuerza con vídeos con voz centrados en lo importante. Con la teoría también se incluyen esquemas e imágenes para ayudar a aclarar los conceptos más complejos.
La combinación de los tres estilos de aprendizaje facilita la comprensión de los conceptos. Pero es mucho más costosa de crear que una simple sucesión de vídeos grabados como si fuese una clase en directo.
Cuando se busca un curso de programación, se debe elegir uno en el que el material combine múltiples formas de transmitir las ideas, en cada caso la más apropiada, para aumentar las posibilidades de comprender y retener la información.
El curso online que tienes en mente adquirir para formarte, ¿qué tipo de material te ofrece? ¿Vídeo tan solo? ¿Una buena teoría para los conceptos importantes? ¿Te enseña "recetas" o te enseña conceptos? ¿Te ofrece material de consulta y repaso posteriores para cuando termine la formación?
2.- Aprendizaje basado en proyectos

Tratándose de temas de formación técnica, el aprendizaje kinestésico - aprender haciendo - es la forma más efectiva y eficiente de asimilar la materia.
El aprendizaje se produce cuando hay una transformación de la información en un producto de trabajo. Durante este proceso de aprendizaje es natural que las tareas de programación se compliquen y que no funcionen las cosas, porque así se aprende de forma contextual. La máxima de campusMVP es que la mejor forma de aprender a programar es programando. Pero no de cualquier manera.
La formación siempre debe aspirar a una proporción de 80/20. El 80% del tiempo se debería estar programando o pensando en cómo resolver tareas de programación, revisando tu propio código hasta dar con la solución más adecuada. El 20% restante se debería estar leyendo y viendo vídeos.
Siempre hay que tener en cuenta si el curso que se quiere realizar tiene un proyecto o una aplicación que se desarrolla a lo largo del mismo. La programación en casos reales desarrolla la memoria para adquirir habilidades básicas. Y estos proyectos no deben ser los típicos laboratorios paso a paso en los que te van diciendo lo que tienes que hacer, sino ofrecer un punto de partida y uno de destino, unas pocas indicaciones para el camino, y que los pasos adecuados los decidas e implementes tú, con apoyo de un tutor, y basándose en todo lo aprendido hasta ese momento en el curso.
"Pegarse" con el código es la única forma de aprender. Lo otro son "recetas" que no servirán para la vida real, cuando no estés bajo condiciones de laboratorio.
Eso es realmente el aprendizaje kinestésico: aprender haciendo. Averigüa si la formación que te interesa te da "mascado" cómo hacer las cosas o si te obliga a decidir y trabajar con apoyo de un tutor experimentado. Si te dicen que "aprendes sin esfuerzo": o no aprenderás nada útil o te mienten.
3.- Posibilidad de resolución de problemas
Esto está muy relacionado con lo anterior, pero va un poco más allá...
Desafortunadamente, muchos cursos programación no dan la opción a que los estudiantes resuelvan problemas. La mayoría de los cursos enlatados basados en vídeo muestran a alguien programando para que los alumnos lo imiten sin pensar. El resultado siempre sale.
Y, aunque es importante replicar también las "recetas" que te explican cuando estás empezando en una materia, sin el entrenamiento adecuado para resolver problemas, será muy difícil encontrar una salida profesional en el mundo de la programación. Un buen curso debe ofrecer retos que se sepa que te van a provocar problemas cuando los resuelvas.
Esto se debe a que se necesita práctica en el análisis causa/efecto y en la comprensión de la jerarquía, la depuración de errores y la refactorización. A veces, el objetivo que se persigue con los problemas es secundario. Lo importante es el aprendizaje que surge al intentarlo, al tropezar, al encontrarse con problemas y no tanto el hecho de conseguir un resultado concreto.
Esta es probablemente una de las mayores fortalezas de campusMVP: siempre se están resolviendo problemas y, esto es muy relevante, aprendiendo a gestionar cierto grado de frustración.
Siendo esto importante, tampoco hay que abusar. Para prevenir la fatiga, es aconsejable que se establezcan objetivos para la resolución de un cierto número de problemas a la semana o en cada módulo.
La formación que estás considerando ¿te ofrece la oportunidad de resolver problemas (no proyectos concretos: problemas)? ¿Te obligará a "pelearte" con ellos y a gestionar un poco la frustración? ¿Te apoyarán cuando no puedas resolverlos?
4.- La figura del tutor
No hay nada peor que estar trabajando en un problema dentro de un curso y toparse con un muro de hormigón y no tener a dónde acudir en busca de ayuda. Se intenta hacer todo lo que se puede, incluyendo un montón de búsquedas en Google, pero nada. Esto hace que el aprendizaje se frene en seco, y por eso es tan importante que el curso disponga de un tutor para ayudar al alumno a "desbloquearse".
Un tutor con contacto directo, no un foro donde a lo mejor te contesta un compañero mañana, dentro de una semana o a lo mejor nunca.
Esto es crucial. Si no se tiene una manera de obtener respuestas a las preguntas de manera oportuna y rápida, uno se olvida de lo que ha aprendido, hay ciertas cosas que no va a ver nunca o se siente desmotivado para seguir avanzando.
¿La formación que estás sopesando hacer te ofrece un tutor con contacto directo y tiempo de respuesta garantizado? ¿Quién es ese tutor? ¿Quizá el mismo profesional reconocido que ha diseñado el curso?, como en campusMVP.
5.- El mapa del tesoro: hitos y plazos

Aunque un buen marketing puede hacer pensar que puedes aprender a programar en un mes, sin esfuerzo y conseguir un trabajo increíble, lo más probable es que no sea así. Y eso está bien. Aprender a programar o una nueva tecnología lleva tiempo.
Cada uno aprende a su propio ritmo, pero es importante que se fijen objetivos realistas para saber en cada momento dónde deberíamos estar, tener hitos a corto, medio y largo plazo para ayudarnos a planificar y no desanimarnos por el camino.
Los grandes cursos proporcionan puntos de referencia que ayudan a motivarte y a animarte a seguir adelante. En cualquier curso de campusMVP siempre tienes claros los hitos y objetivos en cada momento:
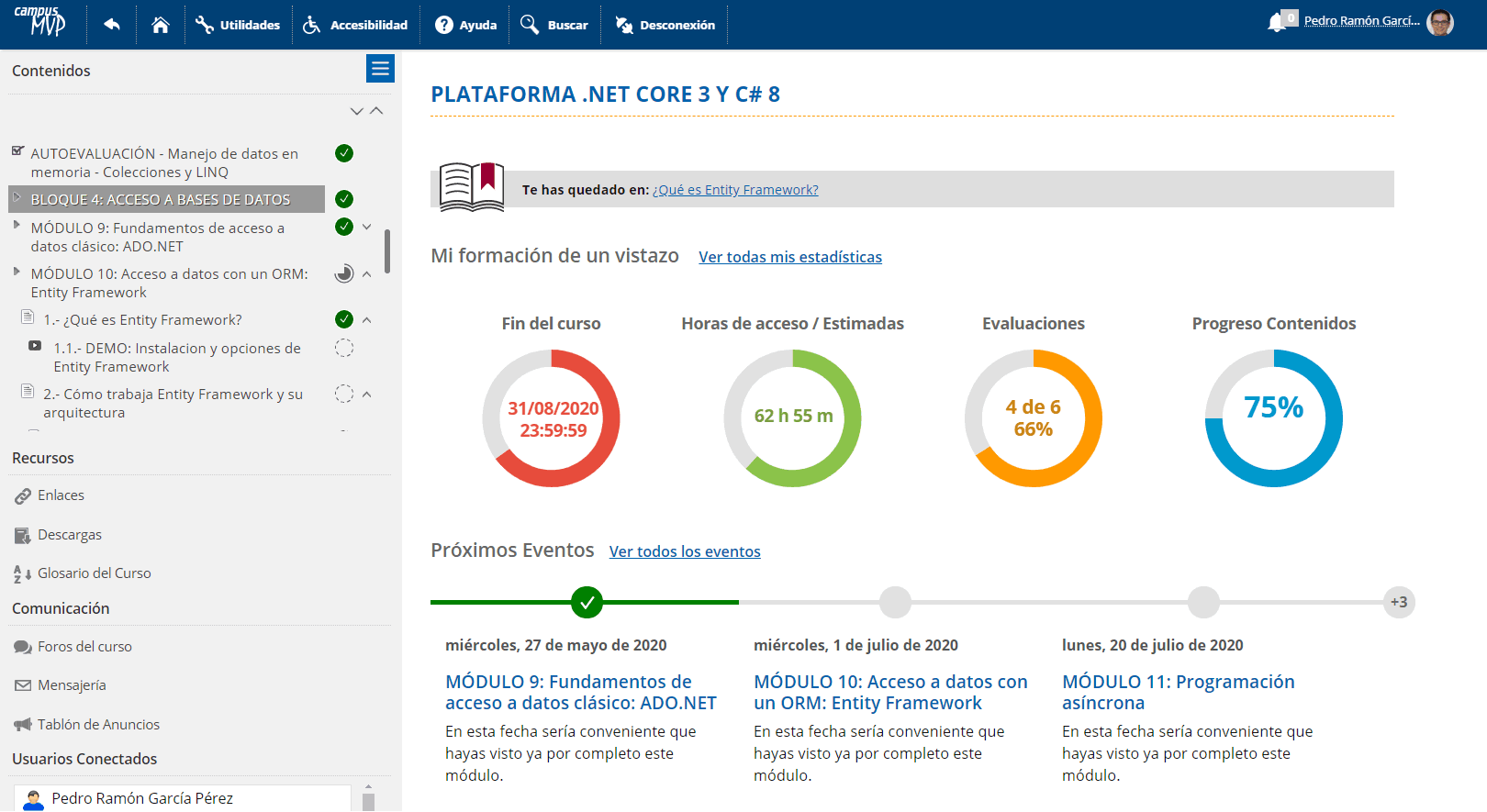
Desde el instante en el que accedes al curso conoces perfectamente en dónde estás respecto al aprendizaje total, qué llevas bien y qué llevas mal, cuál es el próximo hito que tienes en el futuro inmediato, cuánto te queda y las estadísticas clave de tu aprendizaje.
Esto no está reñido con que tengas libertad para ir a tu ritmo y decidir cómo estudiar. Solamente te ayuda a tener una brújula por la que guiarte. Que no es poco.
En formación online esto es especialmente importante o corres el riesgo de no terminar la formación nunca. Por eso también entra dentro de nuestra filosofía el hecho de que todas las formaciones tengan una fecha de fin concreta y cerrada. Y por eso cerca del 90% de nuestros alumnos finalizan la formación con éxito.
Aunque esto es algo que muchas veces se pasa por alto al valorar un curso, es sumamente importante para la salud mental mientras se aprende y para lograr aprovechar y terminar la formación online. La sensación de logro hace maravillas para en la psique humana.
¿Cómo estás de fuerza de voluntad pra estudiar a pesar del día a día de tu trabajo? La formación que estás considerando ¿ofrece hitos claros o deja a tu libre albedrío qué haces y cuándo lo haces? Si tienes toda la vida para hacerlo, es probable que no lo hagas en tu vida. Si te cobran una cuota mensual, les importa que pagues todos los meses, no que aprendas en el tiempo adecuado.


 En el transcurso del evento BUILD esta madrugada,
En el transcurso del evento BUILD esta madrugada, 

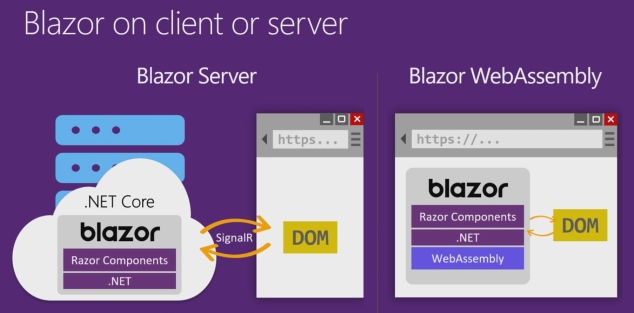










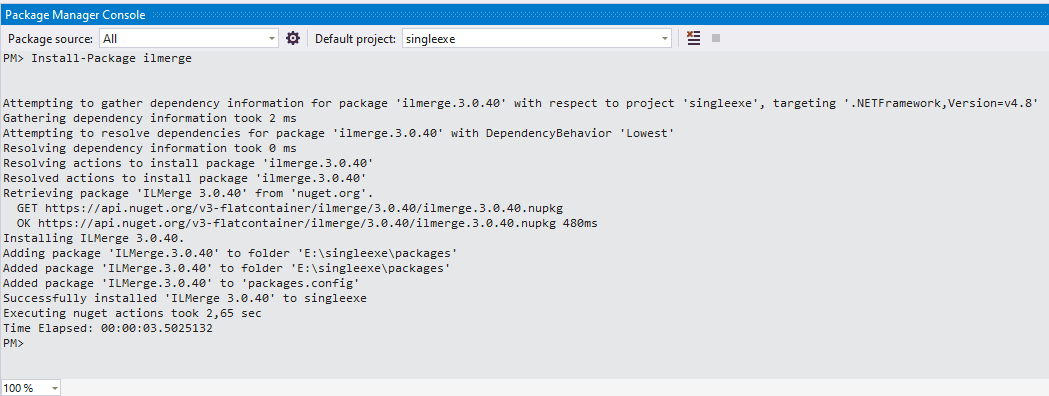
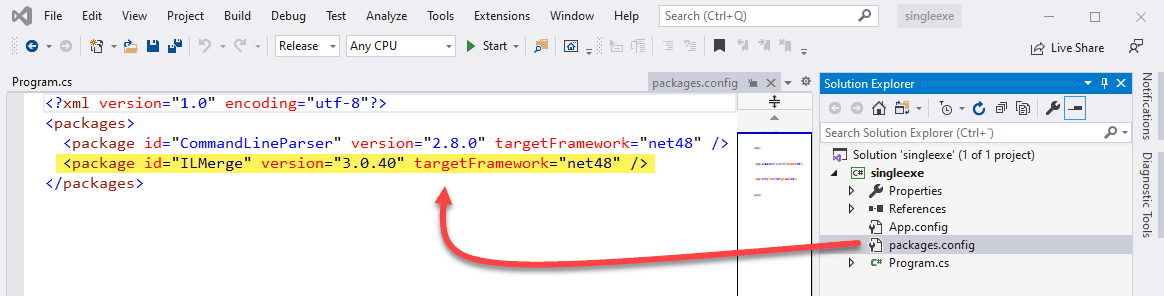
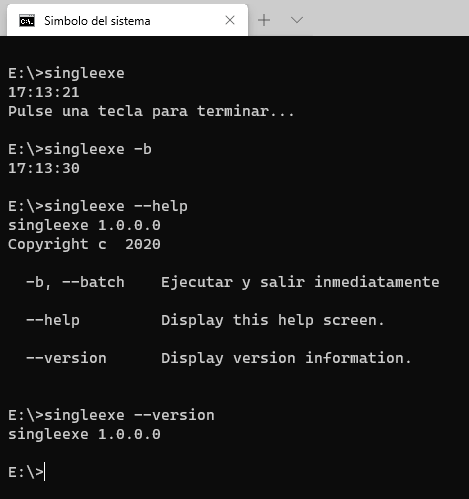
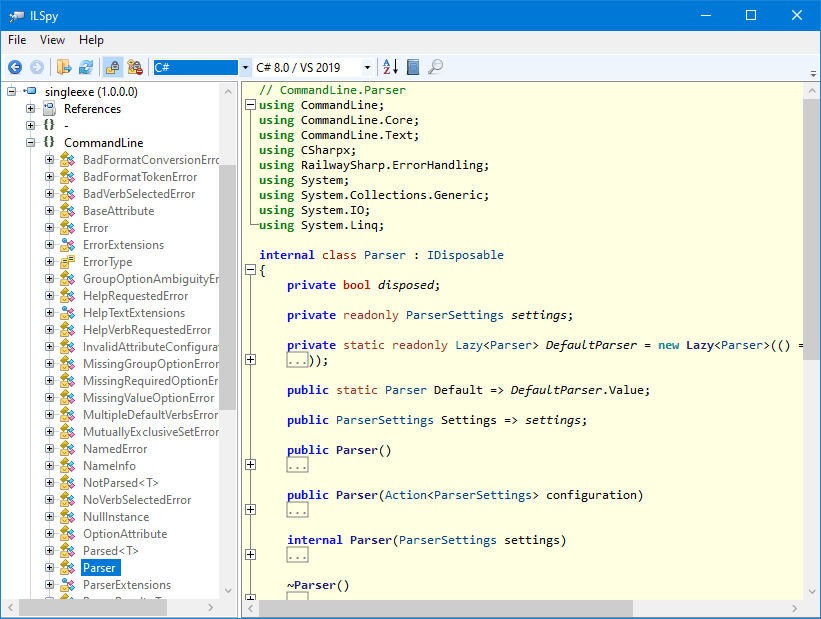
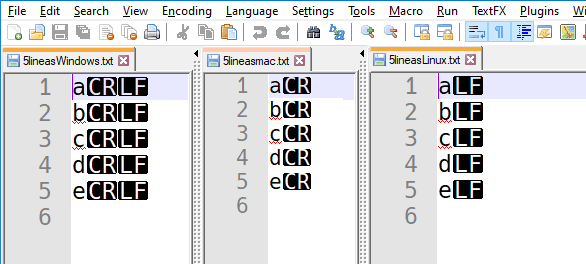 Como seguramente sabrás, cada vez que en tu teclado pulsas la tecla
Como seguramente sabrás, cada vez que en tu teclado pulsas la tecla 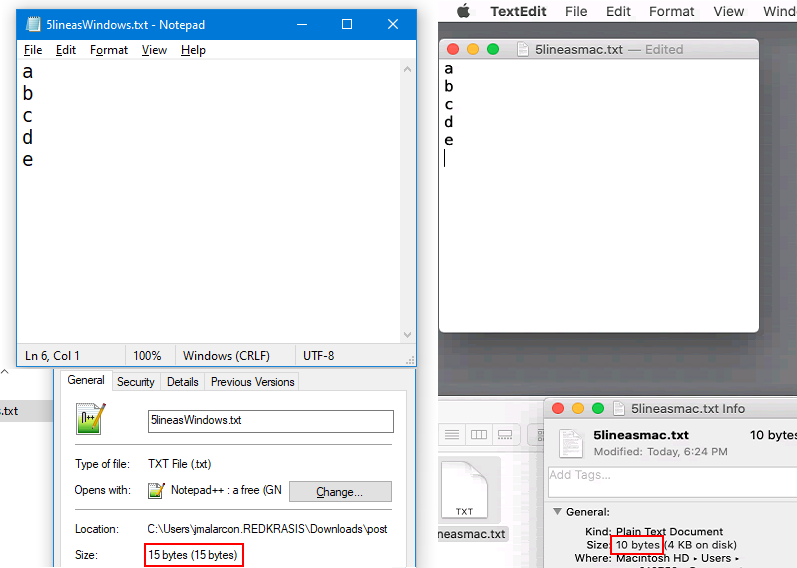
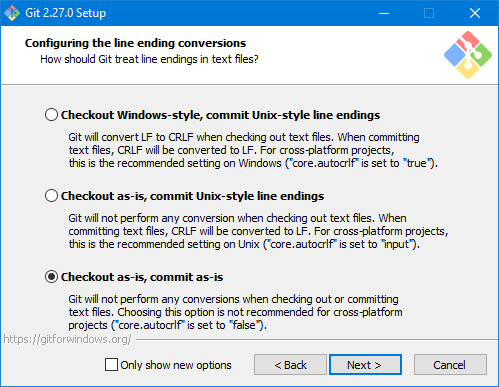
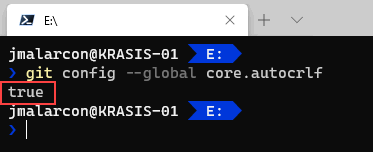
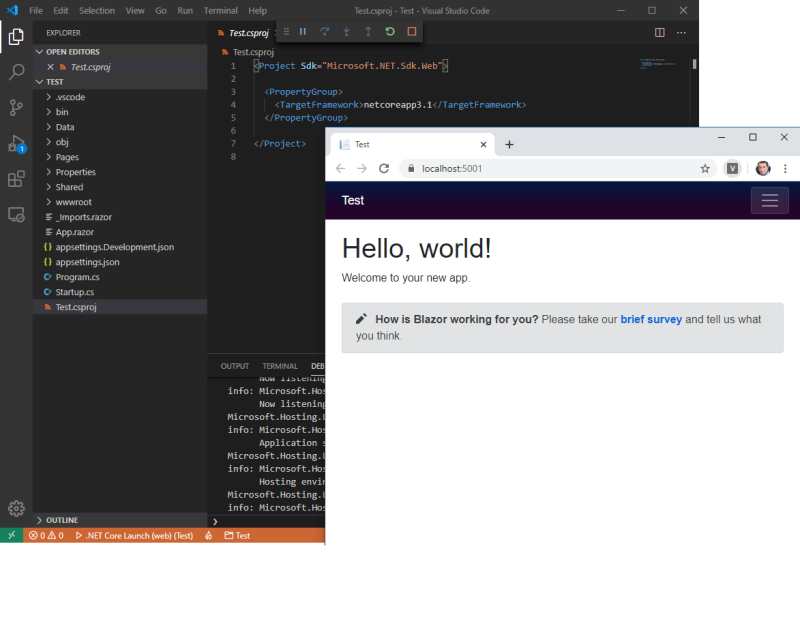
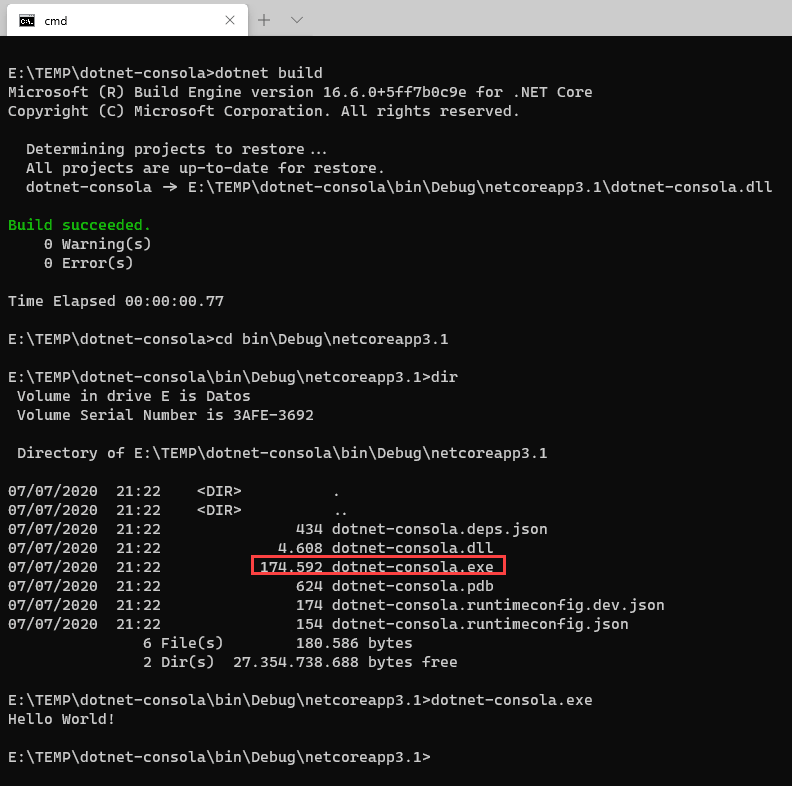
 Cuando compilas una aplicación con .NET Core de cualquier tipo, tienes dos formas básicas de hacerlo:
Cuando compilas una aplicación con .NET Core de cualquier tipo, tienes dos formas básicas de hacerlo:

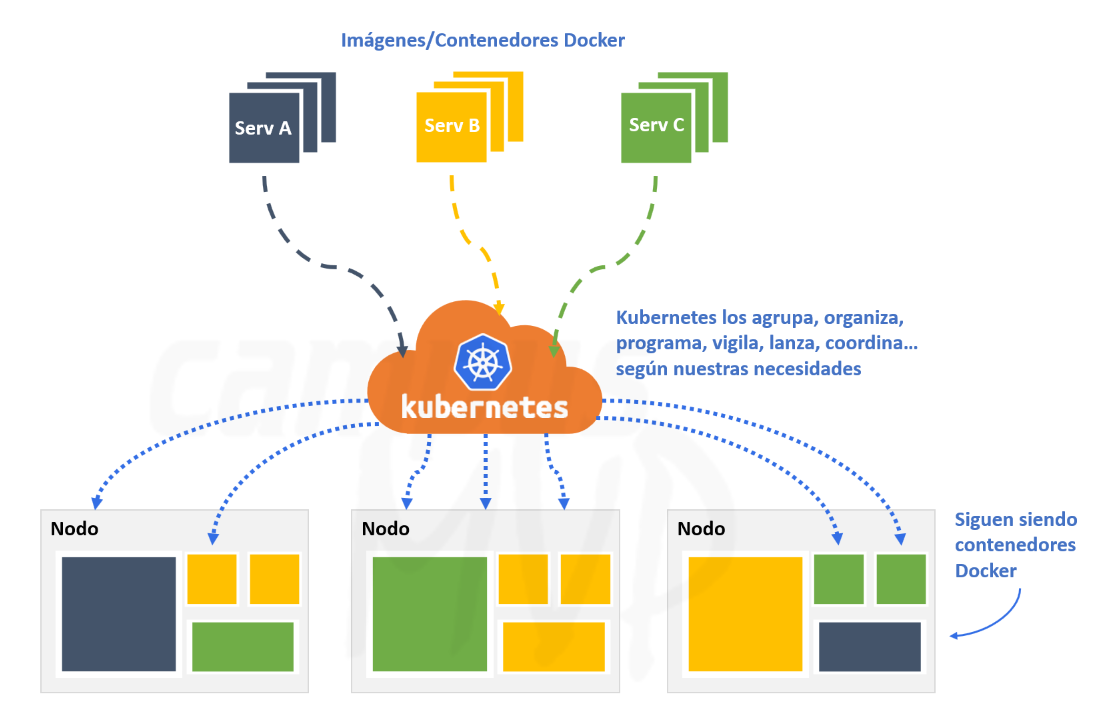



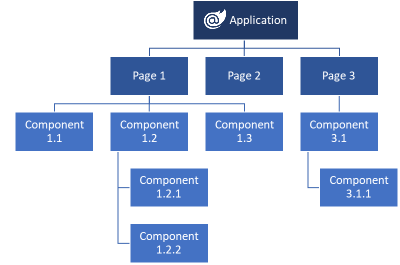
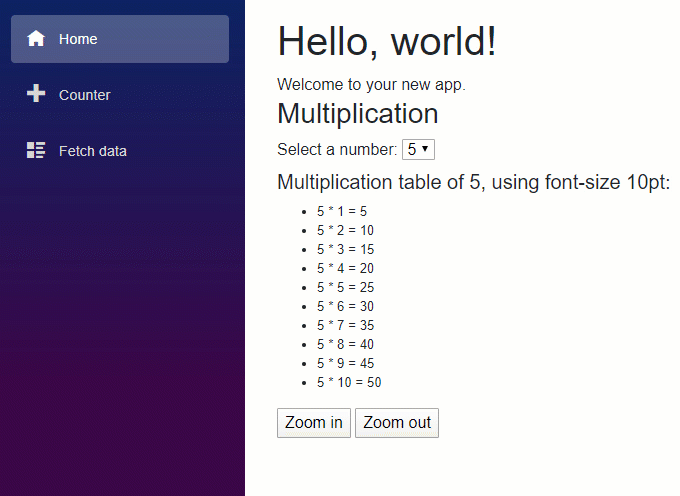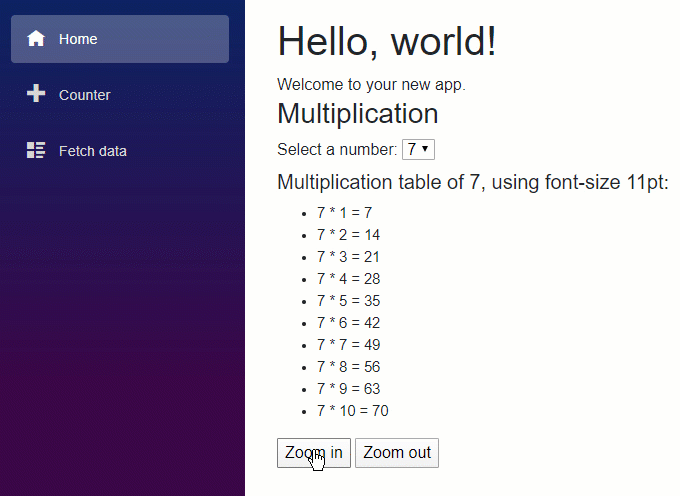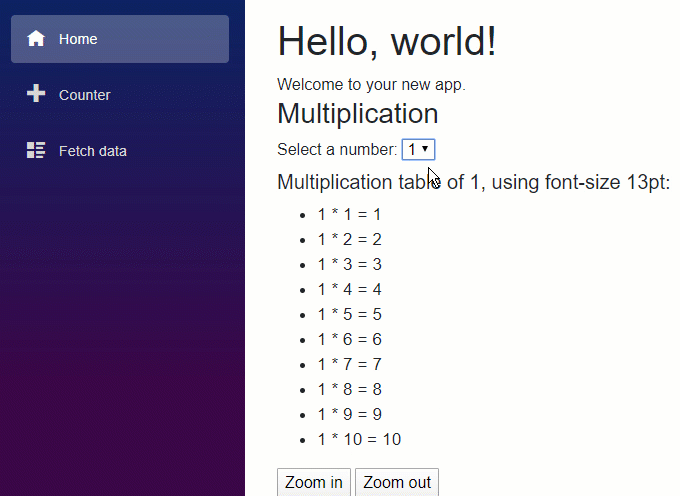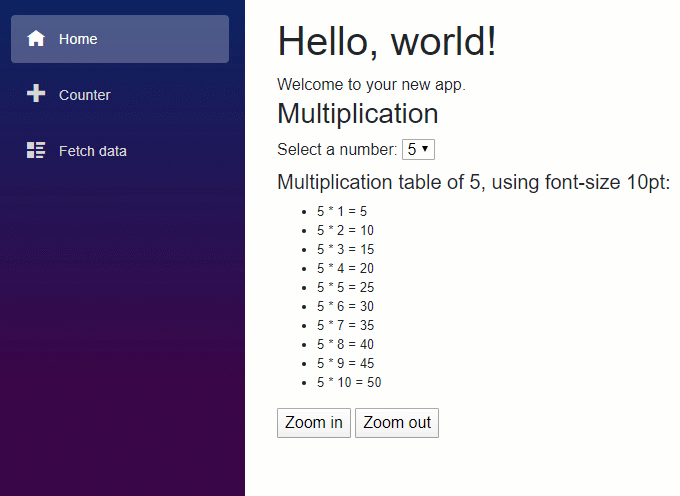
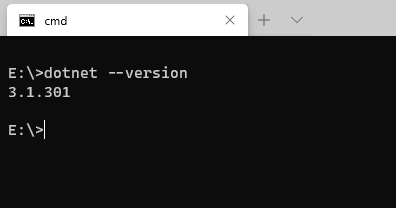
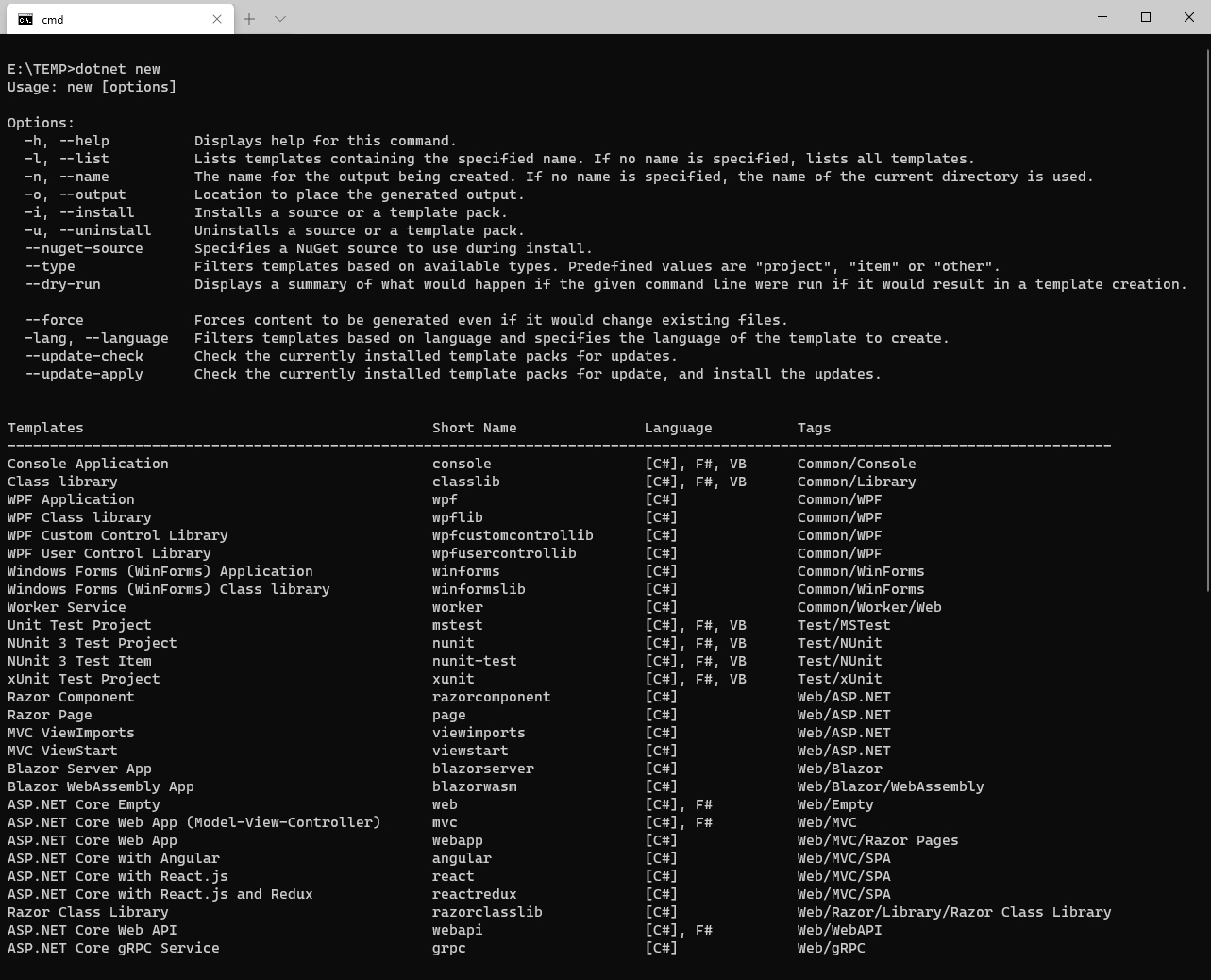
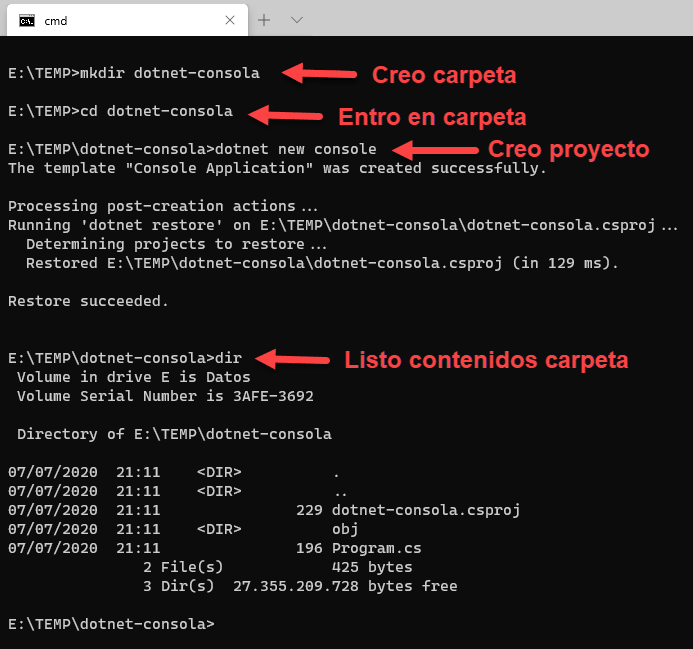
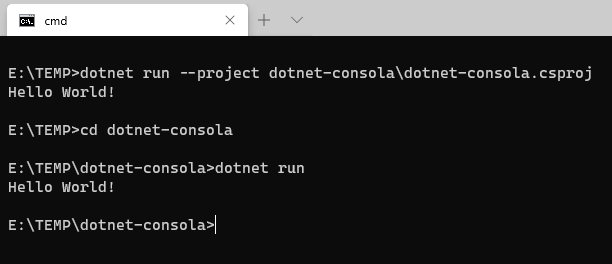
 En este artículo vamos a repasar los pasos básicos para crear una sencilla aplicación con .NET Core para que puedas hacer una primera toma de contacto y comprobar lo sencillo que es empezar.
En este artículo vamos a repasar los pasos básicos para crear una sencilla aplicación con .NET Core para que puedas hacer una primera toma de contacto y comprobar lo sencillo que es empezar.


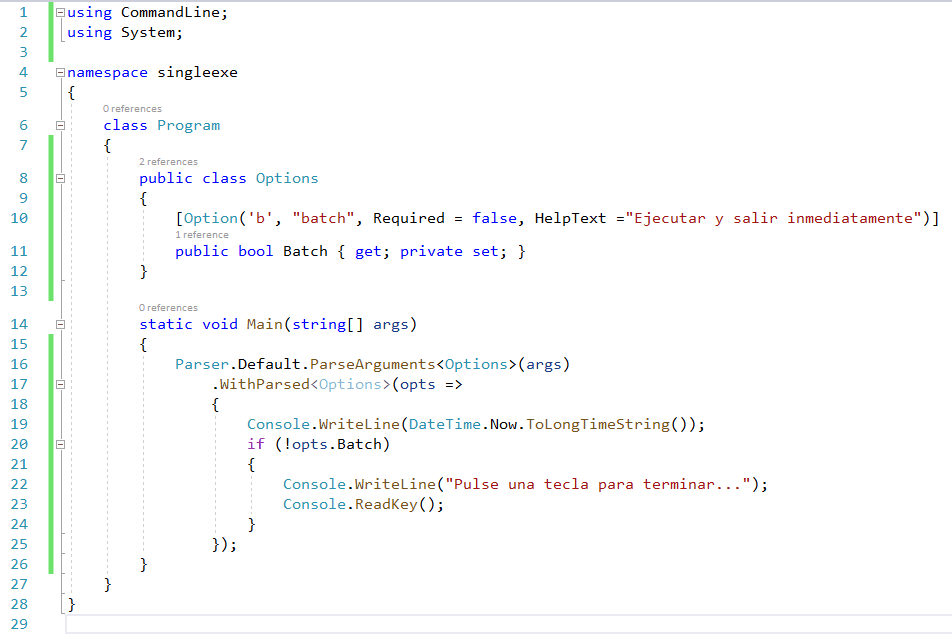
 Además del polimorfismo, una característica que permite a la plataforma Java tratar homogéneamente objetos heterogéneos, de los que habitualmente no se conoce su tipo concreto, el lenguaje Java cuenta con otro mecanismo con el mismo fin: los tipos genéricos.
Además del polimorfismo, una característica que permite a la plataforma Java tratar homogéneamente objetos heterogéneos, de los que habitualmente no se conoce su tipo concreto, el lenguaje Java cuenta con otro mecanismo con el mismo fin: los tipos genéricos.

