
Angular decidió lanzar el día 11 del mes 11 su última versión major del framework, la número 11 (las casualidades no existen 😁). En esta versión han dado una idea de cuál es su actual foco y probablemente el de varias versiones posteriores, otorgando una gran importancia a la estabilidad y al ecosistema por encima de nuevas funcionalidades, algo por otro lado muy necesario.
Como siempre, antes de entrar en detalle, recordemos qué significa que Angular haya sacado su nueva versión major siguiendo el versionado semántico:
- Versión major: se esperan cambios que puedan romper antiguas versiones y es probable que se requieran ciertos pasos (manuales o automáticos) para actualizar la aplicación.
- Versión minor: se pueden introducir pequeñas novedades, pero siempre con retrocompatibilidad con versiones anteriores.
- Versión patch: básicamente introducen soluciones a bugs conocidos.
Si bien esta versión de Angular no contiene tantos cambios sobre los que haya que hacer migración, como pudimos tener por ejemplo con Angular 9, ng update nos hará el trabajo más llevadero en ese sentido. Este comando nos permitirá realizar la migración de nuestra aplicación sin apenas esfuerzo.
Operación Byelog
Cómo mencioné al inicio del post, el principal foco de la versión 11 ha sido mejorar la estabilidad del ecosistema, un proceso al que en Angular llaman “Operación Byelog”. Este proceso consiste en aumentar los recursos destinados por Angular en sus tres monorepos con el objetivo de cerrar issues y mezclar Pull Requests (PR) que son importantes para la comunidad.
Esto es algo muy interesante porque, a finales de noviembre y principios de diciembre de 2020, tan solo el repositorio principal de Angular ya cuenta con alrededor de 2.500 issues abiertas y 400 PR pendientes de ser revisados 😱:
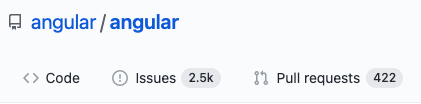
La Operación Byelog pretende, no sólo ir mejorando estas estadísticas, sino que cada vez que se abra un issueéste pueda ser resuelto en un plazo máximo de dos semanas (un esfuerzo para nada desdeñable con el volumen que manejan). Y como parte de este esfuerzo Angular ha publicado este roadmap en su web para poder estar informados de sus actuales prioridades, y en qué partes del framework están poniendo el foco en cada momento.
Conversión de tipografías externas a recursos en línea
Angular 11 introduce la automatización en el proceso de compilación de tus tipografías, que se convierten por defecto en recursos en línea. Esto consiste en que, durante el proceso de compilación, se descargan las fuentes tipográficas que uses en tu aplicación, y se añaden dentro de una etiqueta style, lo que permite cargarla más rápido después, sin tener que esperar a parsear primero el CSS devuelto y luego comenzar la descarga de los recursos asociados.
El principal beneficiado de este proceso es el SEO ya que mejora notablemente el tiempo del primer pintado. Para aquellos desarrolladores que se han preocupado en todo momento de los web vitals o las estadísticas en lighthouse de su aplicación, esta funcionalidad quizás no les aporte demasiado ya que tendrán solucionado este problema usando otros métodos, pero siempre está bien para futuras situaciones que Angular lo proporcione automáticamente sin necesidad de que hagamos nada.
Mejoras en el entorno de desarrollo
La nueva versión de angular introduce dos nuevas mejoras respecto a nuestra experiencia de desarrollo mientras programamos con el framework:
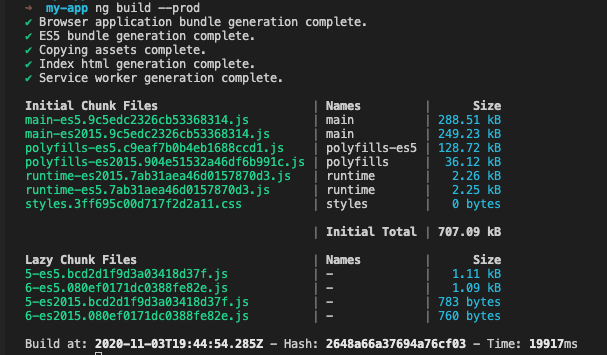
Mejora en el logging
Ahora, durante el proceso de compilado, Angular nos informará de mejor forma la información del estado de la aplicación, para que sea más fácil de leer:
HMR
Desde mi punto de vista, la introducción del reemplazo de módulos en caliente (o hot module replacement) es, sin duda alguna, la funcionalidad del momento en Angular. Esta nueva mejora permite cargar automáticamente en los componentes los cambios que hagamos al desarrollar, tanto de estilos como de lógica, sin necesidad de recargar la página (en "caliente"), lo que mejora considerablemente tanto la inversión de tiempo como la experiencia de desarrollo mientras programamos.
La puedes activar simplemente lanzando el servidor de desarrollo con la opción --hmr:
ng serve --hmr
TypeScript y TSLint
Como en la mayoría de versiones de Angular, cada vez que se actualiza la major se actualiza también la versión de TypeScript. El motivo es que, al contrario que Angular, TS no sigue el versionado semántico, sino que cada versión del lenguaje puede introducir cambios que necesiten de alguna migración en tu código y, esto para Angular, sólo se puede hacer en una major, como hemos visto al principio.
En el caso de Angular 11 la versión de TypeScript que usa es la 4.0.
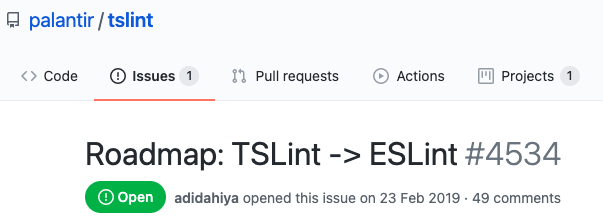
En la versión anterior Angular hacía uso de TSLint, como linter por defecto para código TypeScript. Se ha sabido que esta herramienta va a dejar de mantenerse, así que para Angular 11 han decidido migrar a ESLint, tal y como recomendaban los maintainers de TSLint en la issue correspondiente. Por ello, si no has necesitado nunca añadir modificaciones en la configuración por defecto de TSLint, probablemente te espere una migración sencilla. Por el contrario, si tu configuración es muy a medida, no te quedará otra opción que informarte sobre dicha migración (en el issue tienes bastantes datos al respecto):
Una última cosa sobre este apartado: desde Angular 10 han ido mejorando los tipos que usan en el framework. Con el cambio de linter se mejora también la integración entre ellos, permitiendo (siempre y cuando se active esta opción a la hora de ejecutar ng new) una mejor detección de errores de tipado y de posibles fallos. Esta mejora se debe en parte al motor de renderizado Ivy, aparecido en la versión 9, que permite conectar correctamente la lógica y analizarla teniendo en cuenta la template del componente. Pero aún queda camino por recorrer ya que todavía quedan ciertas partes del framework que utilizan ViewEngine, el anterior motor de renderizado.
Webpack 5
La nueva versión de Webpack salió unos pocos días antes que la de Angular y se puede usar de forma experimental en el framework añadiendo simplemente el siguiente código en el archivo package.json:
"resolutions": {
_ "webpack": "5.4.0"_
}
Seguramente el principal motivo por el que no lo han añadido de forma definitiva es porque la nueva versión de Webpack, aunque introduce muchas mejoras, también introduce varios cambios de compatibilidad con la versión anterior. Uno de los más problemáticos es la desaparición de los polyfills automáticos para navegadores antiguos (esencialmente Internet Explorer).
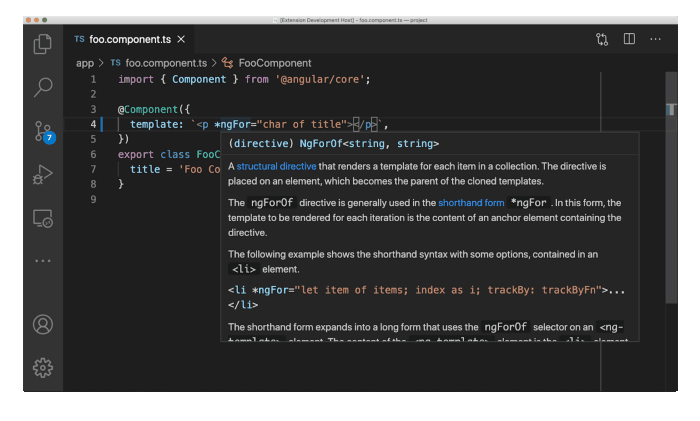
Servicio de lenguaje
El servicio de lenguaje de Angular es el encargado de recomendarnos todas esas buenas prácticas y advertencias de posibles errores mientras escribimos nuestro código. En esta versión Angular ha introducido ciertas mejoras descriptivas, aunque este servicio aún funciona sobre ViewEngine, el antiguo motor pre-Ivy. En principio se espera su desaparición o más bien migración a Ivy en futuras versiones, lo que nos permitirá inferir tipos entre nuestro código y el template:
En resumen
Angular continúa con su proceso de mejora interno, lo que a nosotros como desarrolladores nos viene estupendamente, ya que se espera que le den algo más de "cariño" a los repositorios en las próximas versiones. Y sobre todo una mejor experiencia de desarrollo, algo en lo que parece que ya llevan un tiempo enfocándose y es de agradecer.
Para versiones futuras cabe esperarse aún más mejoras relacionadas con los tipos, y también una reducción considerable en el número de problemas o mejoras pendientes que hay en GitHub.
Y por supuesto, el curso de Angular de CampusMVP ya está actualizado con esta nueva versión.

 Una de las novedades más interesantes
Una de las novedades más interesantes 








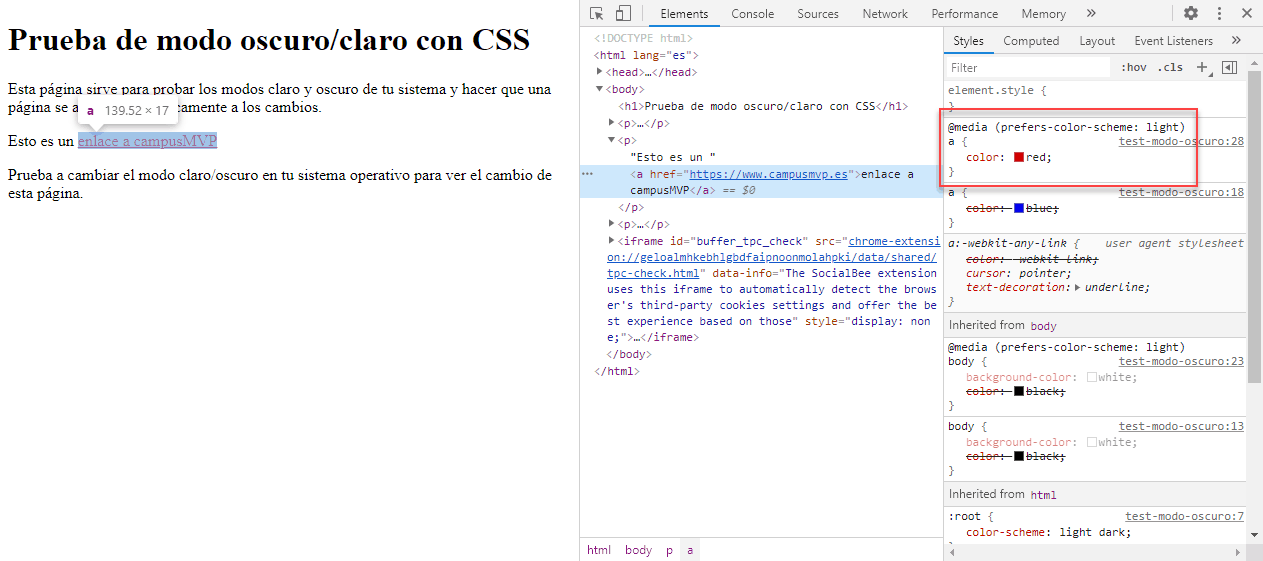
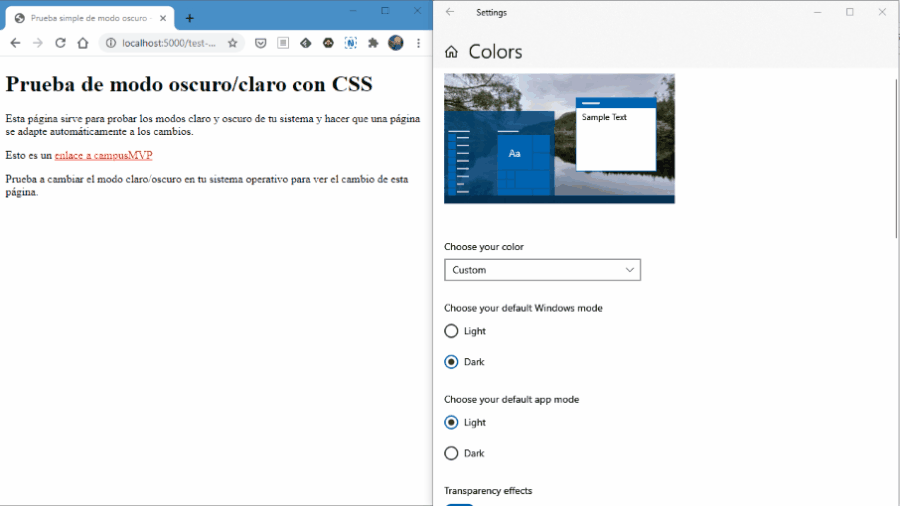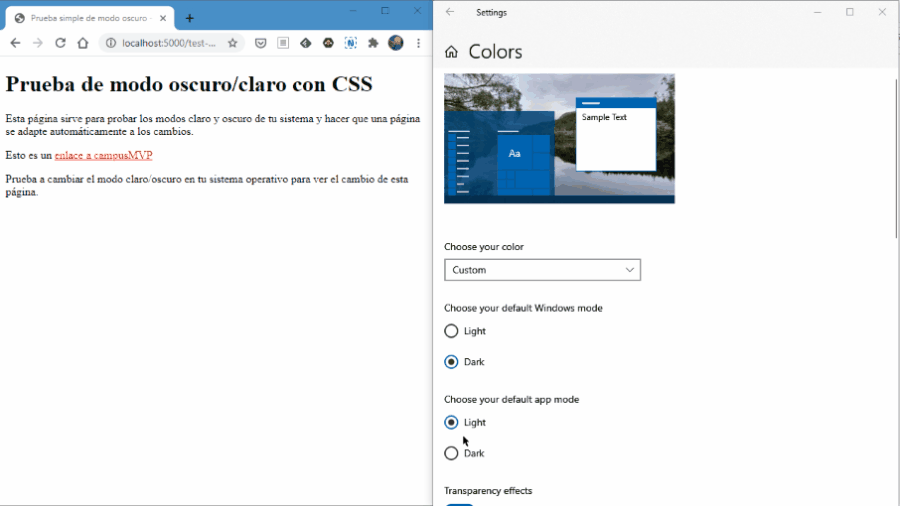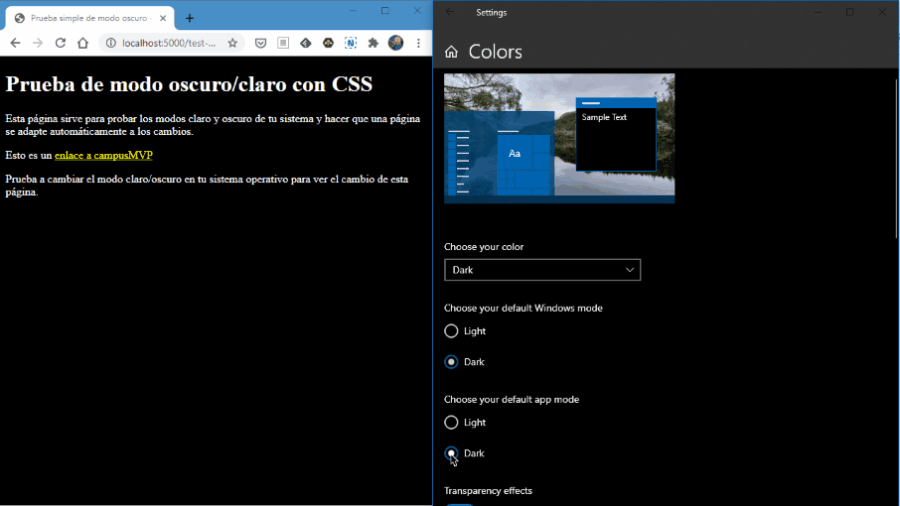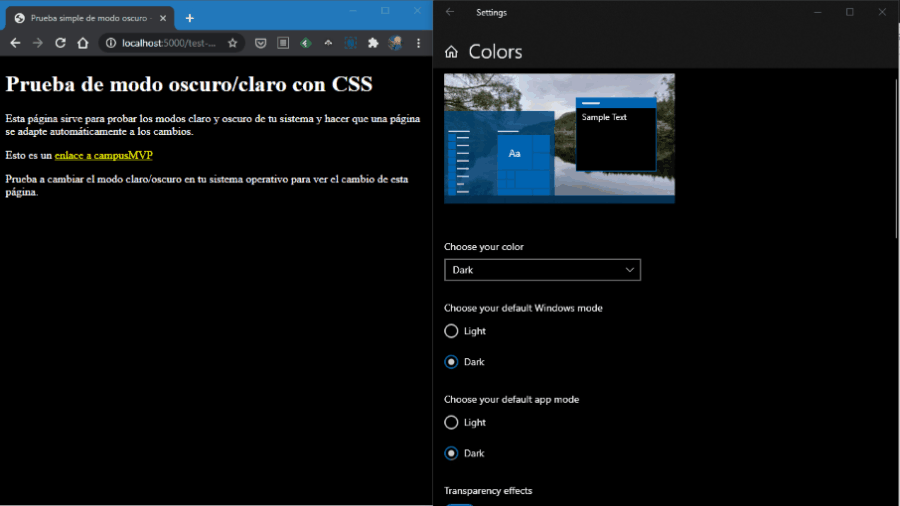


 Esta semana empezamos con un experimento que esperamos que salga bien, os sea útil y seamos capaces de seguir haciéndolo. Se trata de un noticiario semanal en vídeo en el que os contaremos en 2 o 3 minutos las principales noticias que se hayan producido en el sector, haciendo especial hincapié en cuestiones relacionadas con la programación.
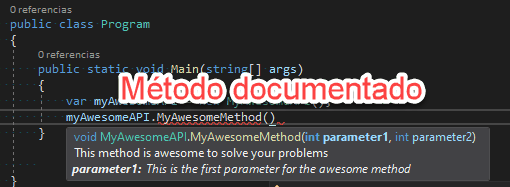
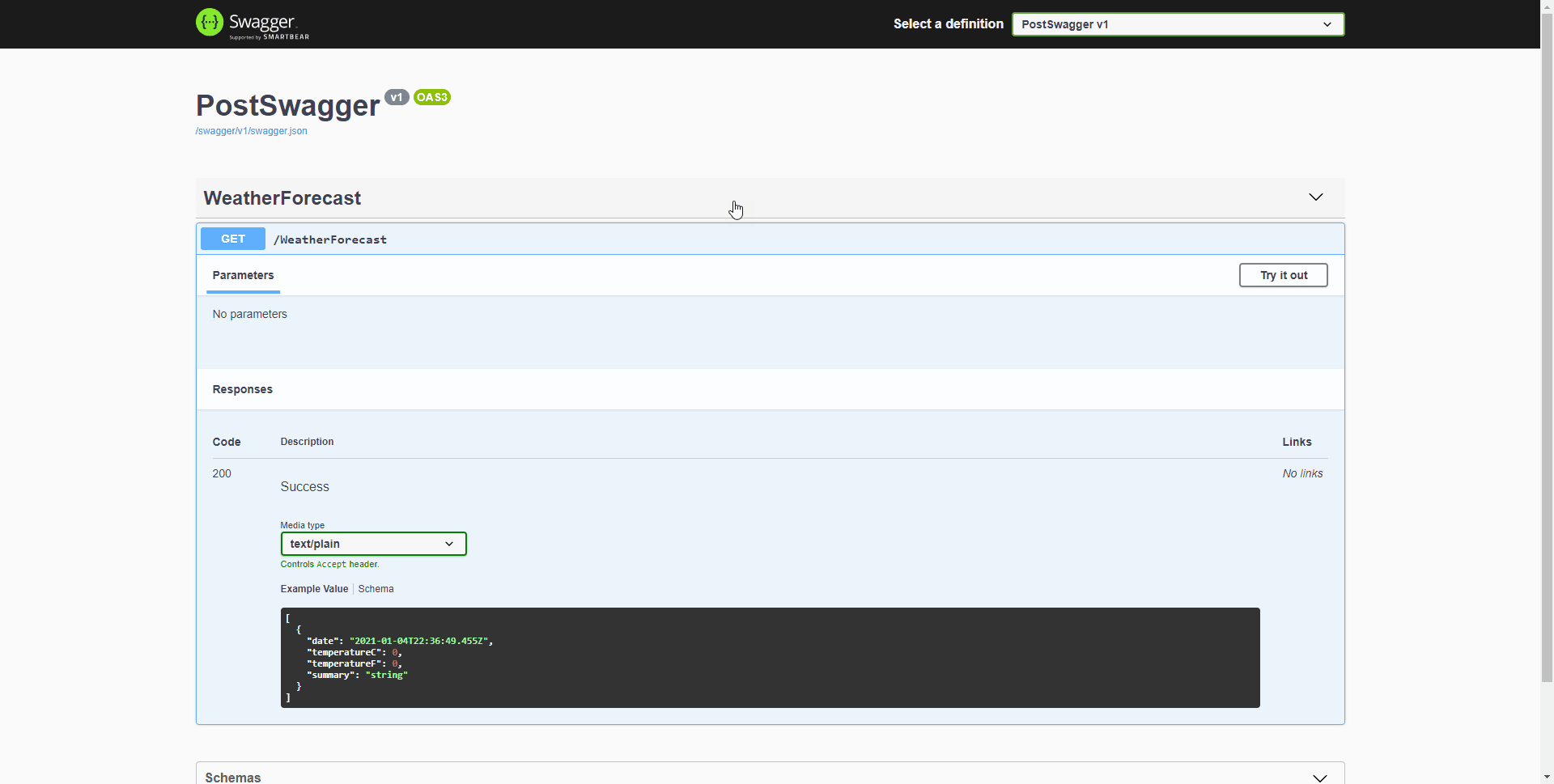
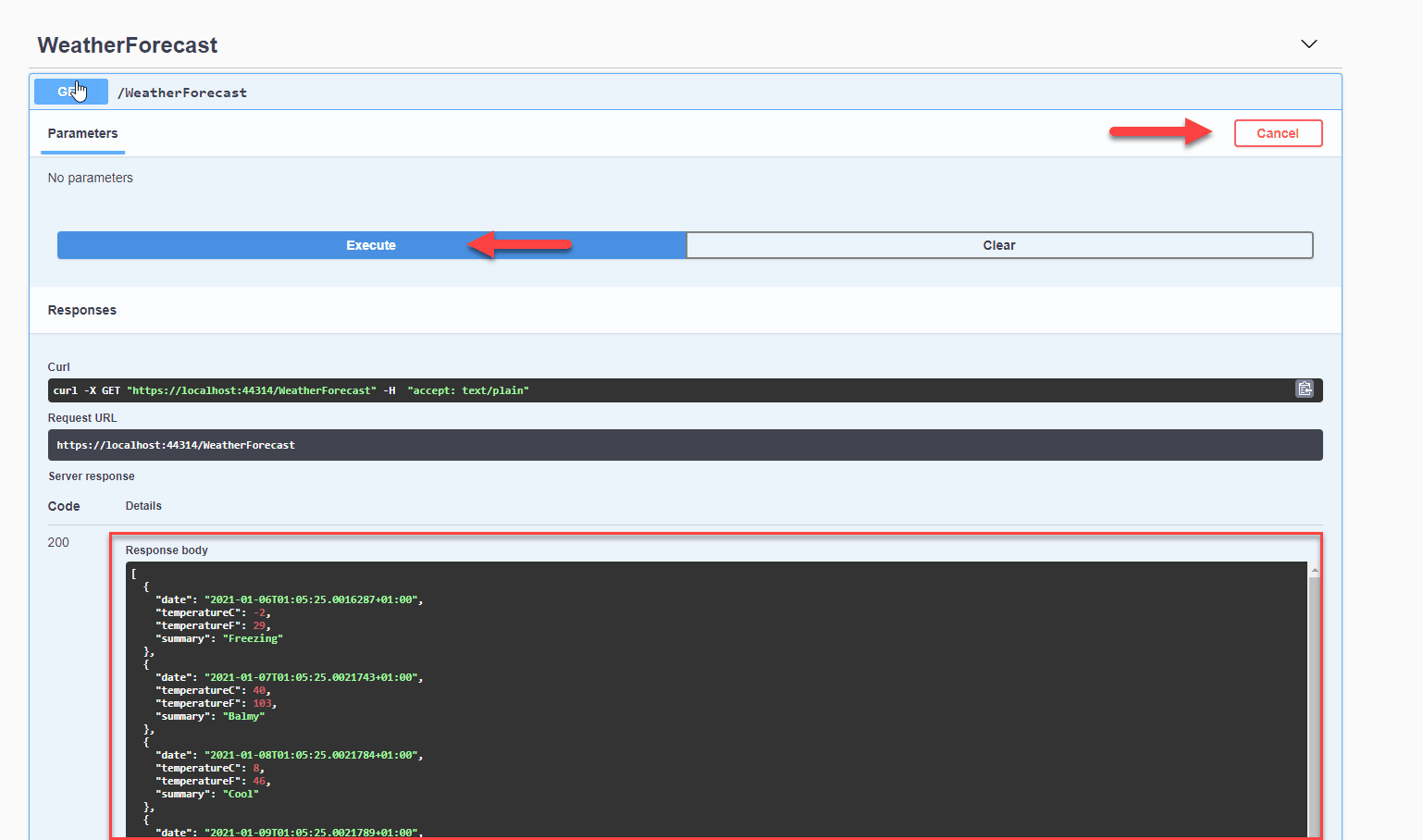
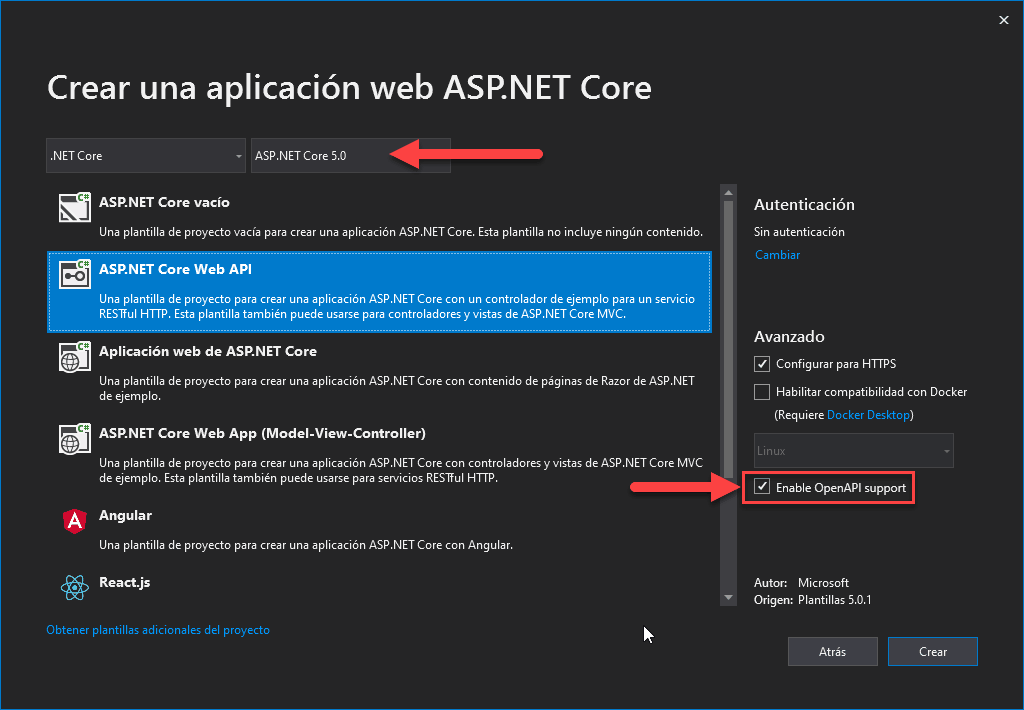
Esta semana empezamos con un experimento que esperamos que salga bien, os sea útil y seamos capaces de seguir haciéndolo. Se trata de un noticiario semanal en vídeo en el que os contaremos en 2 o 3 minutos las principales noticias que se hayan producido en el sector, haciendo especial hincapié en cuestiones relacionadas con la programación. Quien más y quien menos en este mundo del software, alguna vez ha tenido que escribir una biblioteca de clases (mal llamada librería) o una API REST. O, al menos, ha tenido que modificarla. Y como profesionales que somos, siempre documentamos y explicamos el funcionamiento para que los consumidores puedan usarla fácilmente ¿verdad? 😜
Quien más y quien menos en este mundo del software, alguna vez ha tenido que escribir una biblioteca de clases (mal llamada librería) o una API REST. O, al menos, ha tenido que modificarla. Y como profesionales que somos, siempre documentamos y explicamos el funcionamiento para que los consumidores puedan usarla fácilmente ¿verdad? 😜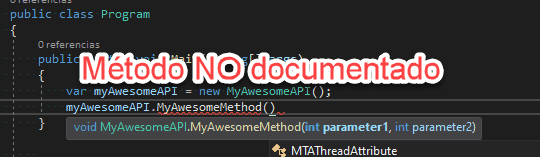


 Esta semana en nuestro noticiario, tenemos novedades sobre Oracle, el fin de la vida de .NET Core 2.1, el dominio mundial de WordPress, las nuevas gafas de realidad aumentada de Lenovo y varias noticias de menor calado. Además, una fe de erratas al principio, y una noticia de campusMVP en exclusiva.
Esta semana en nuestro noticiario, tenemos novedades sobre Oracle, el fin de la vida de .NET Core 2.1, el dominio mundial de WordPress, las nuevas gafas de realidad aumentada de Lenovo y varias noticias de menor calado. Además, una fe de erratas al principio, y una noticia de campusMVP en exclusiva. Hace unos meses la Comisión Europea publicó el
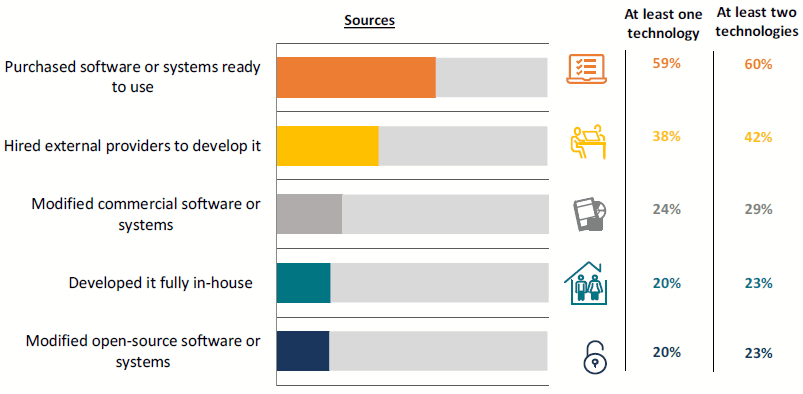
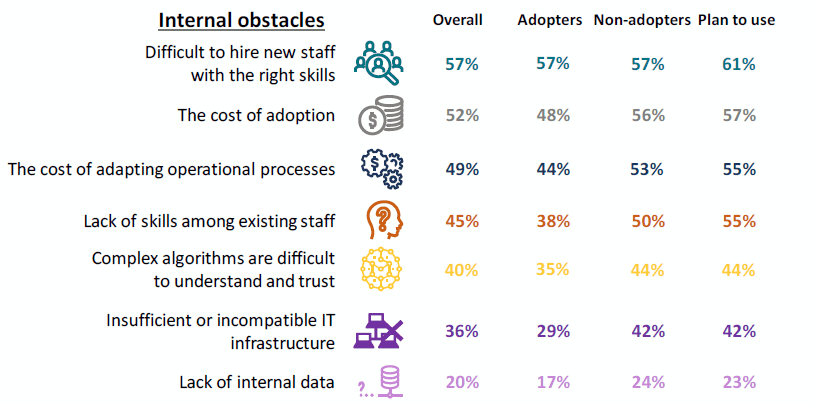
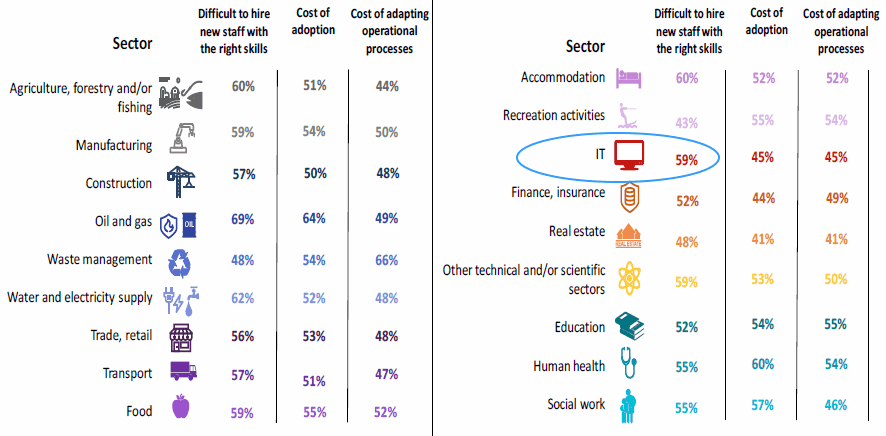
Hace unos meses la Comisión Europea publicó el 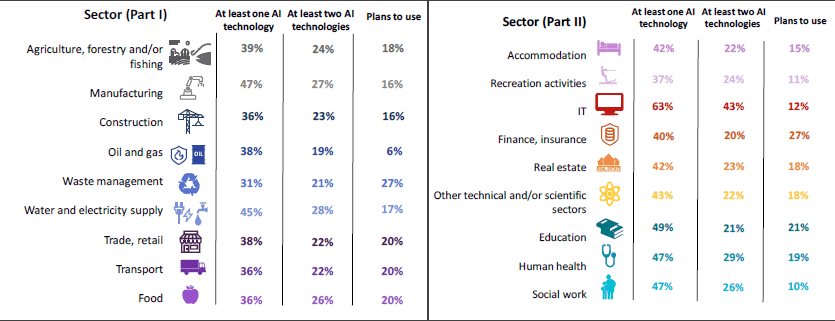



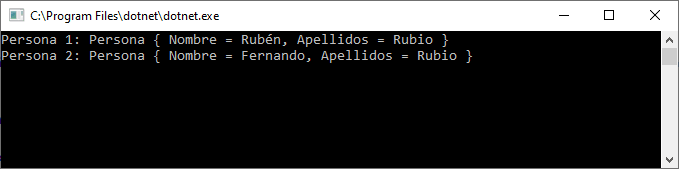
 Una de las grandes novedades que se presentaron con .NET 5 y C# 9, fueron los registros.
Una de las grandes novedades que se presentaron con .NET 5 y C# 9, fueron los registros.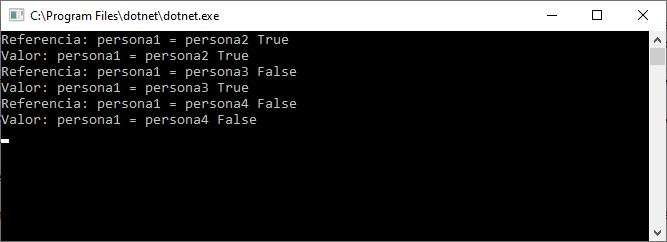

 [youtube:UQOeoVqKuvg]
[youtube:UQOeoVqKuvg]

 [youtube:96sSb0Pg5d4]
[youtube:96sSb0Pg5d4]

 No es la primera vez, ni mucho menos, que
No es la primera vez, ni mucho menos, que 

