NOTA: este artículo es una traducción de "Ok.. let me explain: it's going to be Angular 4.0, or simply Angular" de Juri Strumpflohner.
Y a partir de ahora llamémosle solo Angular...
El pasado 8 y 9 de Diciembre de 2016 se celebró el NG-BE, la primera conferencia de Angular en Bélgica. Igor Minar (jefe de desarrollo de Angular) asistió como presentador e hizo algunos anuncios interesantes relacionados con el itinerario de lanzamientos de Angular. Intentad leer todo el artículo hasta el final, hay un par de cosas importantes.
Igor fue extremadamente abierto y transparente sobre las novedades, incluso en su forma de presentarlo. Creó la presentación de forma abierta el día antes de la conferencia:
I'll be conducting a major open source experiment at @ngbeconf tonight at 10pm downstairs in the main room. Come if you want to participate.
— Igor Minar (@IgorMinar) December 8, 2016
Bueno pues aquí va:

¿Por qué Angular 4? ¿Incluso por qué Angular? ¿Qué está pasando aquí?
Angular usa SEMVER
Allá por septiembre de 2016 cuando se lanzó la nueva versión de Angular, el equipo de Angular también anunció que iban a cambiar a Versionado Semántico (SEMVER).
Como su propio nombre indica, el Versionado Semántico consiste en añadir significado al número de las versiones. Esto permite a los desarrolladores no solo razonar ante cualquier subida de versión que se haga, sino incluso permitir que herramientas como NPM lo hagan de forma automática y segura por nosotros.
Una versión semántica incluye tres números:

Cada vez que arregles un bug y liberes, incrementas el último número, si se añade una nueva funcionalidad, se incrementa el segundo número, y cada vez que incorpores un cambio no compatible hacia atrás, que rompe con lo anterior, incrementas el primero.
"Un cambio incompatible sucede cuando como desarrollador y usuario de una biblioteca, tienes que ajustar tu código tras una nueva versión."
¿Y esto que implicaciones tiene para el equipo de Angular? Como con todo software que evoluciona, siempre podrá producir algún cambio incompatible hacia atrás. Por ejemplo, que se produzca un error de compilación debido a bugs existentes que pasaron inadvertidos con la anterior versión del compilador TypeScript, cualquier cosa que pueda romper una aplicación al subir de versión en Angular exige que el equipo de Angular pase al siguiente número de versión, cambiando el primer número.
Para ser claros, como también mencionó Igor en su presentación. Ahora mismo, incluso subiendo de versión de la dependencia de TypeScript de Angular, de v1.8 a v2.1 o v2.2 y compilar Angular con él, técnicamente causaría una incompatibilidad. Así que se están tomando SEMVER muy, muy en serio.
Nota de campusMVP: esto significa que, incluso aunque no haya nada nuevo, si cambian de compilador de TypeScript y esto puede producir algún problema que rompa la aplicación, deberían cambiar la versión. Por ello, por ejemplo, cambiar de una hipotética versión 5 a la 6 no significa necesariamente que haya cambio alguno, aunque a lo mejor sí... Eso significa que habrá que estar muy atentos a cada versión para estar seguros.
¡Los cambios incompatibles no tienen que ser dolorosos!
Las personas que han estado siguiendo a la comunidad de Angular desde hace un tiempo, definitivamente saben de lo que estoy hablando. Pasamos de Angular 1 a Angular 2, y fue un cambio total, con nuevas API's, nuevos patrones. Eso era obvio: al final Angular 2 se ha reprogramado desde cero (aunque hay opciones de migración disponibles).
Cambiar de la versión 2 a la versión 4 ó 5… no será como migrar de Angular 1. No será una re-programación completa, será un simple cambio en algunas de las bibliotecas del núcleo que exigen un cambio principal de versión SEMVER. Además, habrá las correspondientes fases de obsolescencia para permitir que los desarrolladores ajusten su código.
Internamente en Google, el equipo de Angular usa una herramienta para gestionar subidas de versión automáticas, incluso de cambios incompatibles. Esto es algo que todavía requiere una planificación más en detalle, pero el equipo está muy centrado en hacer que esta herramienta esté disponible de forma generalizada, muy probablemente durante este año 2017 justo a tiempo para Angular 5.
Solo "Angular"
Como ya has podido deducir, el término "Angular 2" habrá sido abandonado cuando lleguemos a la versión 4, 5 etc... Dicho esto, debemos empezar a llamarle simplemente "Angular" sin el sufijo de la versión.
Es simplemente Angular
Además, deberíamos empezar a evitar las bibliotecas, GitHub/NPM prefijadas con ng2- o angular2-.
Also, we should start avoiding GitHub/NPM libraries prefixed with
ng2-orangular2-.@toddmotto@manekinekko@jdfwarrior@schwarty but please don't call projects ng2- or angular2-, etc.
— Igor Minar (@IgorMinar) December 10, 2016
Directrices para la nomenclatura
El equipo de Angular ha lanzado directrices oficiales de cómo nombrar bibliotecas, libros y artículos.
Versión corta: usa el nombre "AngularJS" para cualquier versión 1.x , y simplemente "Angular" para cualquier versión 2 o posterior. El objetivo es ser lo más consistente posible, particularmente hacia el futuro, mientras se reduce la carga del mantenimiento causado por las inconsistencias de nomenclaturas del pasado.
Básicamente intenta usar el número de la versión, a no ser que sea totalmente necesario para evitar ambigüedades. Por ejemplo:
- Usa "Angular" para las versiones 2.0.0 y posteriores (por ejemplo, "Soy desarrollador de Angular", "Esto es un MeetUp de Angular", "El ecosistema de Angular crece rápidamente")
- Usa "AngularJS" para describir versiones 1.x o posteriores
- Usa el número de la versión "Angular 4.0" "Angular 2.4" cuando se necesite hacer referencia a una versión concreta (por ejemplo, al hacer referencia a una funcionalidad recién implementada- "Esta es una presentación de la funcionalidad x, introducida Angular 4", "Propongo este cambio para Angular 5"...)
- Usa el semver completo al informar de un bug (por ejemplo, "Este problema existe por ahora hasta Angular 2.3.1")
Además en artículos de blogs, cursos, libros o cuando te refieras a una versión muy en concreto de Angular, considera añadir una linea de cabecera indicando:
Este artículo usa Angular v2.3.1.
Eso te ayudará a evitar confusiones entre tus lectores, especialmente cuando estás escribiendo sobre API's concretas.
¿Por qué no la versión 3?
Las bibliotecas nucleares de Angular están en un único repositorio en github.com/angular/angular. Todas están versionadas de la misma manera, pero distribuidas como diferentes paquetes:

Debido al desajuste que existe en la versión del paquete del enrutador, el equipo decidió ir directamente a por Angular versión 4. De esta forma se vuelve a una situación en la que todos los paquetes del núcleo están alineados, haciendo que todo sea mucho más fácil de mantener y ayuda a evitar confusiones en el futuro.
¿Por qué estaba el enrutador alineado ya en la versión 3? Aquí está el anuncio oficial por parte del equipo de Angular cuando sacaron la versión del enrutador.
Nota de campusMVP: esto prueba una vez más lo mal que lo han hecho en los últimos años en lo que se refiere al versionamiento del producto :-S
También es importante entender cómo se está usando e integrando Angular dentro de Google (Igor habla de esto aquí en su presentación). Todas las aplicaciones de Google usan la versión de Angular correspondiente a la actual rama principal (master) de GitHub del repositorio de Angular. Cada vez que se introduce un nuevo commit en la rama master, se integra en el mono-repositorio gigantesco y único de Google, donde también conviven otros productos como Maps, Adsense, etc... Como consecuencia, todos los proyectos de Google que usan Angular hacen pruebas exhaustivas contra esta nueva versión. Esto hace que el equipo se sienta muy confiado a la hora de distribuir una nueva versión, ya que contiene una idéntica combinación de versiones de paquetes de Angular que ya han sido probados dentro de Google. Por ello, el haber alineado todas las versiones tiene muchísimo sentido y hace más fácil mantenerlas con el tiempo, que a cambio ayuda a que el equipo sea más productivo a la hora de sacar nuevas funcionalidades.
¿Cuándo saldrán nuevas versiones principales?
El calendario de lanzamientos de versiones se puede encontrar en el repo oficial de Angular en Github.
El hecho de que puedan ocurrir cambios incompatibles no quiere decir que ocurran cada dos por tres. El equipo de Angular se ha comprometido a actualizaciones con periodos que ocurren en tres ciclos:
- Parches y solución de bugs cada semana
- 3 versiones pequeñas al mes después de cada versión grande lanzada
- Una versión que cambia el número "grande", con un asistente para migración, cada 6 meses.
Nota de campusMVP: Angular 4 salió el 22 de marzo de 2017. Los cambios han sido mínimos, básicamente:
- A la directiva
*Ifse le ha añadido también unelse.- Asignación de variables locales en las propias directivas
Y nada más. O sea, no hay "breaking changes".
Pero entonces, si no rompe la compatibilidad ¿por qué le han subido la versión? Pues porque Angular lo único que dice es que "de haber breaking changes el cambio sucederá en una versión major" pero puede no ser así. Y este ese uno de esos casos.
¿Entonces a qué se debe el cambio de versión si hay tan pocas novedades? Bueno, para nosotros puede que no haya ninguna novedad pero el nombre que le han dado, "invisible-makeover", lo dice todo: internamente el framework ha sufrido una reestructuración increíble y ha dado un salto importantísimo a nivel de rendimiento. Dependiendo de la aplicación, Angular menciona que el tamaño (en kb) de un componente se ha reducido un mínimo de un 60% y dependiendo de lo complejo que sea el componente aún mayor será la mejora, lo cual es una avance sustancial.
Después de Angular 4.0.0 el plan es:
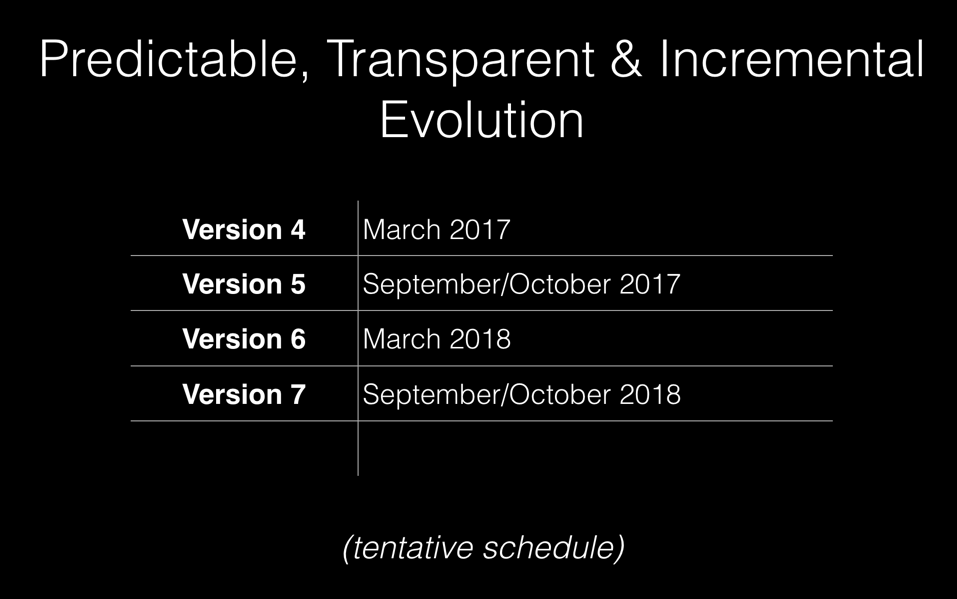
Así que como puedes ver, cada 6 meses aproximadamente habrá versión nueva.
Vídeo: puedes ver la presentación también
[youtube:aJIMoLgqU_o]
Conclusión
Nuevamente, asegúrate de echarle un ojo a las directrices de nomenclatura del equipo de Angular.
Además, hay dos mensajes importantes aquí:
- No te preocupes de los números de las versiones
- No necesitamos evolucionar Angular para evitar otro cambio de Angular 1 a Angular 2, pero deberíamos hacerlo juntos como una comunidad de forma transparente, predecible y constructiva.
También me gustaría darle las gracias a Igor por ser tan abierto a la hora de presentar su información, particularmente sabiendo lo sensibles que son los temas de cambios innovadores que rompen con lo actual. Esto significa mucho y espero que la comunidad caiga en la cuenta por qué todos estos cambios son buenos para todos los implicados.
Gracias a Igor, Brad, Stephen y todo el equipo de Angular por revisar este artículo. Esto una vez más demuestra cuánto se preocupan por su comunidad.

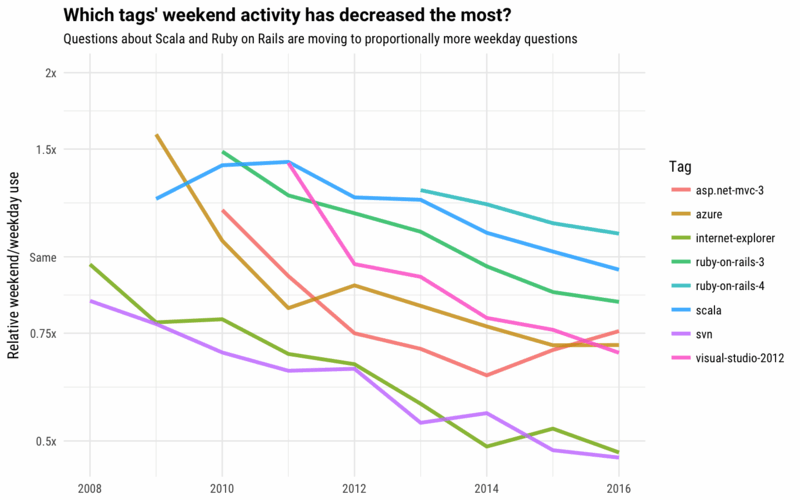
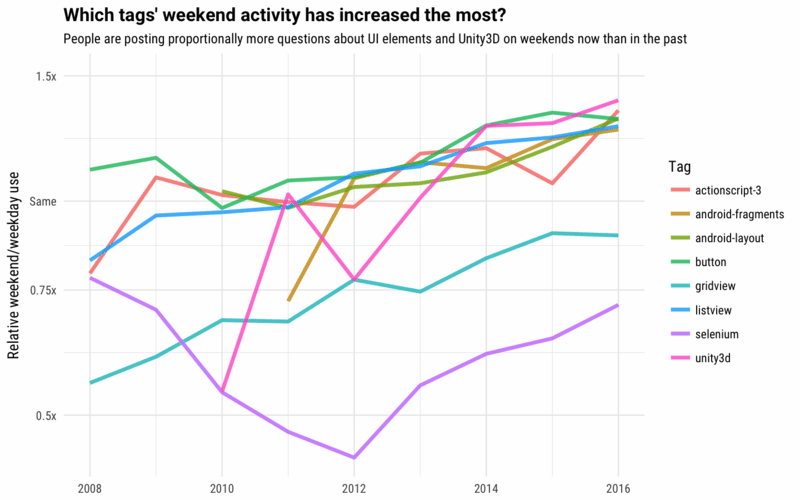
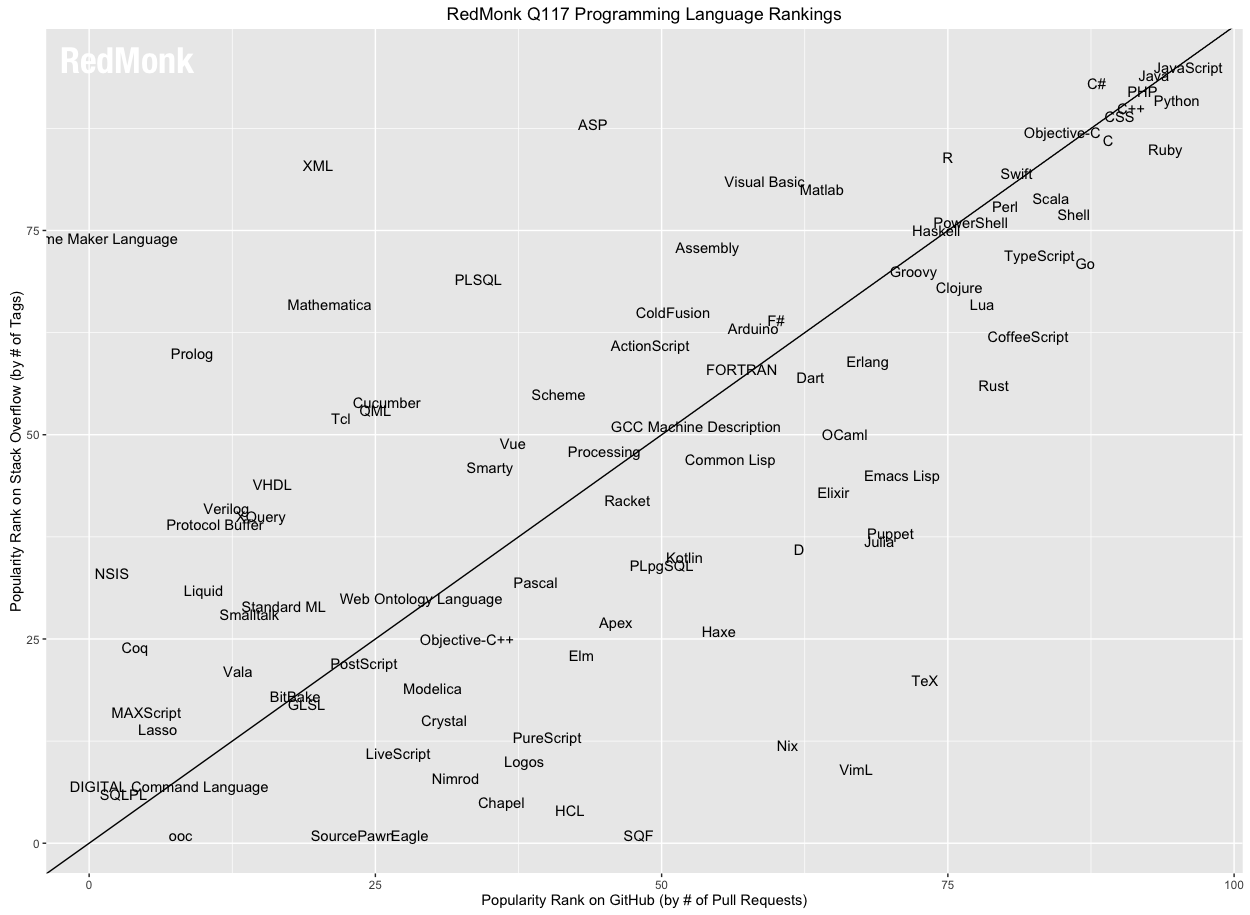 Si comparamos los lenguajes situados en las diez primeras posiciones con los que estaban hace seis meses (
Si comparamos los lenguajes situados en las diez primeras posiciones con los que estaban hace seis meses (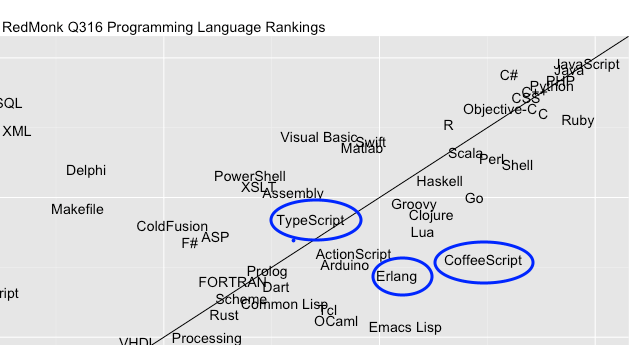


 Chrome es uno de los navegadores más utilizados del mundo. En gran parte su popularidad se debe a lo fácil que es ampliar sus capacidades mediante el uso de extensiones. El problema muchas veces es encontrar la apropiada entre el enorme mar de opciones que tenemos, ya que existen miles de ellas.
Chrome es uno de los navegadores más utilizados del mundo. En gran parte su popularidad se debe a lo fácil que es ampliar sus capacidades mediante el uso de extensiones. El problema muchas veces es encontrar la apropiada entre el enorme mar de opciones que tenemos, ya que existen miles de ellas.



 Si has instalado Java alguna vez habrás visto el siguiente banner:
Si has instalado Java alguna vez habrás visto el siguiente banner:

 Desde siempre, en JavaScript las funciones han tenido una importancia primordial. Por un lado son el mecanismo para tener visibilidades y ámbitos, y además son "ciudadanos de primer orden". Eso significa que en JavaScript se puede, y de hecho se hace constantemente, pasar funciones como parámetros y devolver funciones como resultado.
Desde siempre, en JavaScript las funciones han tenido una importancia primordial. Por un lado son el mecanismo para tener visibilidades y ámbitos, y además son "ciudadanos de primer orden". Eso significa que en JavaScript se puede, y de hecho se hace constantemente, pasar funciones como parámetros y devolver funciones como resultado.



 Los filtros de excepciones son una característica de la gestión de errores de .NET que han estado disponibles en el framework desde siempre. Los programadores de VB.NET han tenido acceso a ellos también desde el origen de los tiempos, pero los "sufridos" programadores de C# se tenían que conformar con simularlos de manera chapucera. No fue hasta la aparición de C# 6.0, allá por el verano de 2015, que los programadores de C# le pudieron sacar partido a esta útil característica por primera vez.
Los filtros de excepciones son una característica de la gestión de errores de .NET que han estado disponibles en el framework desde siempre. Los programadores de VB.NET han tenido acceso a ellos también desde el origen de los tiempos, pero los "sufridos" programadores de C# se tenían que conformar con simularlos de manera chapucera. No fue hasta la aparición de C# 6.0, allá por el verano de 2015, que los programadores de C# le pudieron sacar partido a esta útil característica por primera vez.


 Simplificando mucho las cosas para poder dar una definición corta y comprensible, podríamos decir que la plataforma .NET es un amplio conjunto de bibliotecas de desarrollo que pueden ser utilizadas con el objetivo principal de acelerar el desarrollo de software y obtener de manera automática características avanzadas de seguridad, rendimiento, etc...
Simplificando mucho las cosas para poder dar una definición corta y comprensible, podríamos decir que la plataforma .NET es un amplio conjunto de bibliotecas de desarrollo que pueden ser utilizadas con el objetivo principal de acelerar el desarrollo de software y obtener de manera automática características avanzadas de seguridad, rendimiento, etc...