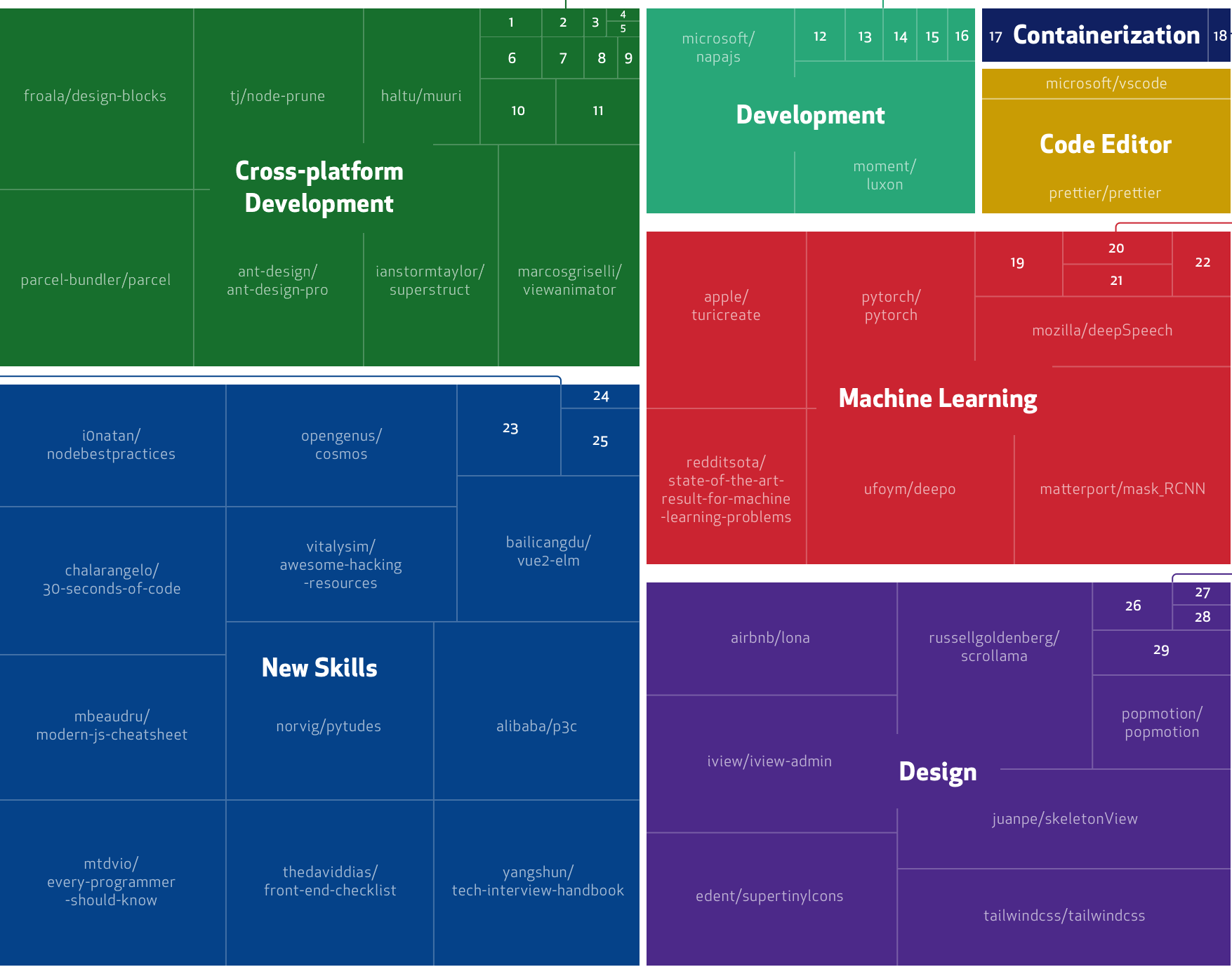
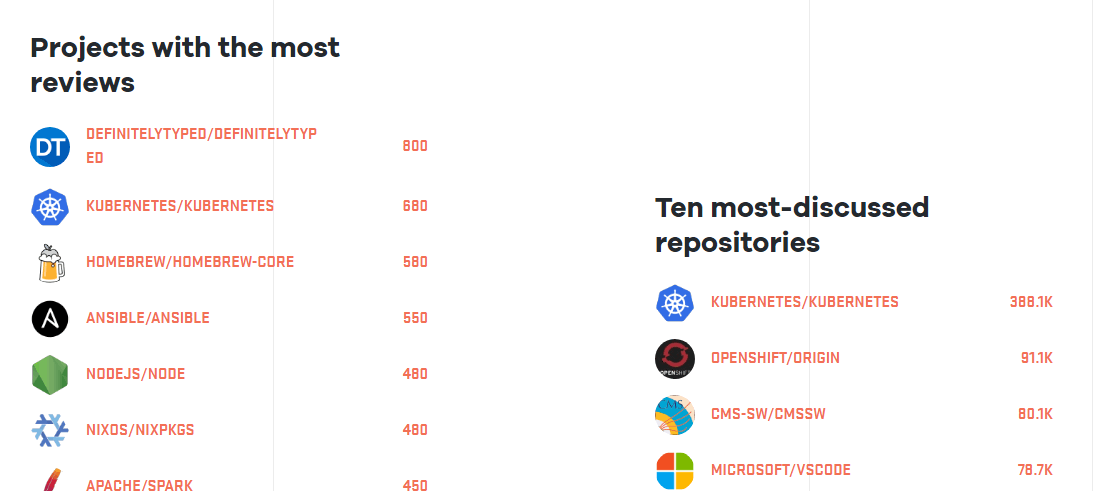
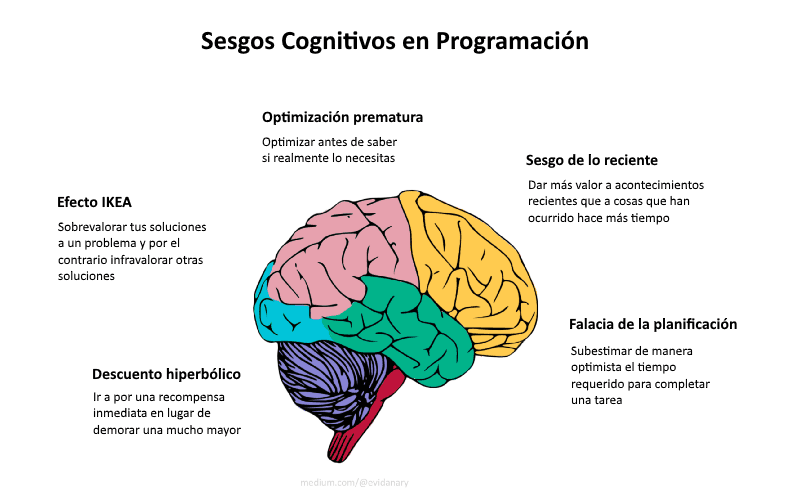
Photo obtenida en Visualhunt
No sé si habrás tenido una experiencia similar. Recuerdo la primera vez que me senté en mi puesto y empecé a recibir formación sobre el software que tendría que utilizar en la empresa de desarrollo de aplicaciones que me acababa de contratar. Windows, Outlook, Internet Explorer, Office... todo iba muy bien hasta que entramos en el apartado del CMS y de la plataforma web (Content Management System o Sistema de Gestión de Contenidos) que usaban en la empresa. ¡Menudo horror!
Obviando ya todo el tema de diseño a nivel visual, aquello era impracticable y tenía graves problemas de funcionalidad. La empresa en concreto estaba especializada en hacer software de contabilidad, pero por alguna extraña razón a uno de los socios-fundadores se le dio por crear su propio CMS para gestionar los contenidos de la web de la empresa ya que ninguna de las opciones del mercado satisfacía sus necesidades. No digo que sobre el papel la idea no fuera buena, pero aquello en ejecución era un verdadero lastre.
Mi experiencia laboral hasta la fecha nada tenía que ver con el sector del software, aunque sí tenía experiencia trabajando plataformas tipo Drupal y WordPress. Algo de CMS sabía, sobre todo a nivel usuario, y ambas plataformas me parecían impresionantemente buenas desde que salieron (15 años después siguen siendo de las más utilizadas y han evolucionado muchísimo).
Pasaron un par de años y aquel CMS no nos los sacábamos de encima ni con ácido. Aquel CMS seguía allí pero ya yo no era la misma persona, había cogido algo de experiencia en el sector de la programación desde la óptica de una persona con una formación no técnica (soy de letras, sí), y empezaba a entender un poco toda la idiosincrasia de los desarrolladores de software y el porqué de la supervivencia de aquel CMS infumable en una empresa líder del sector en la venta de aplicaciones de Contabilidad.
Para poder entenderlo tuve que hacer un ejercicio de empatía. Por ejemplo, a la mayoría de las personas por naturaleza les resulta más fácil y agradable hablar que escuchar. Les resulta más fácil contar su "película" y que los demás la escuchen que al revés.
Para un chef comer la comida de otro colega nunca será tan satisfactorio como cocinar la suya para que la disfruten otros, y para un músico escuchar los temas de otro nunca será tan motivador como tocar sus propias canciones para entretener a los demás.
Pues lo mismo es cierto en el desarrollo de software. La mayoría de los desarrolladores prefieren ser conocidos como aquel fenómeno que desarrolló el framework de interfaz de usuario en la que ahora se basa toda la empresa, que ser simplemente el tipo que hizo la sugerencia de usar Furatto y que le ahorró horas de trabajo a la empresa, por ejemplo.
Para un programador, leer código de otros nunca será tan satisfactorio como escribirlo por sí mismo.
¿Qué hay detrás de todo esto?
Detrás evidentemente está el síndrome del "No inventado aquí", que no es más que una forma irónica y sutil de llamarle a la tendencia que tienen tanto los desarrolladores como las empresas de software de rechazar soluciones perfectamente válidas de terceros para dar salida a problemas de desarrollo, y optar por soluciones desarrolladas internamente en la empresa. Un primo-hermano de este síndrome es el "vamos a reinventar la rueda".
Este síndrome tiene diferentes intensidades, que van desde un sentirse moderadamente reacio a aceptar nuevas ideas hasta el extremo de tener un odio visceral a cualquier software externo rozando ya la "xenofobia". Podemos definir el síndrome de "No inventado aquí" (de ahora en adelante NIA) como una situación en la que una solución externa es rechazada tan solo porque no ha sido desarrollada internamente -en otras palabras, no existen otros factores que dictaminen que un software desarrollado internamente vaya a ser mejor.
Si somos honestos con nosotros mismos, a la mayoría de nosotros nos resulta un poco difícil de admitir que otra persona ha tenido una mejor idea que nosotros, o hizo un mejor trabajo (o al menos tan bueno como el nuestro) a la hora implementarlo de lo que podríamos haberlo hecho nosotros.
Hay también un cierto "instinto de la manada" que conduce irremediablemente al síndrome NIA en algunas organizaciones. Si tradicionalmente la práctica dentro de la organización ha sido la de desarrollar todo el software nuevo internamente, lo más fácil es dejarse llevar por la cultura empresarial en lugar de buscar introducir ideas relativamente radicales de traer todo o, peor, parte de un nuevo software de "fuera".
Muchas empresas de la industria del software caen presa de esta causa del síndrome. Tienen recursos de desarrollo internos, razonan, ¿por qué no deberían utilizarlos, en lugar de fiarse de desarrollos de software de terceros?
La existencia de aplicaciones o bibliotecas heredadas también puede crear un caldo de cultivo ideal para el síndrome NIA. Como diría uno de mis antiguos jefes:
"Nuestros desarrolladores en plantilla han trabajado durante años el desarrollo de esta enorme biblioteca con funciones y métodos para todo, ¡no vamos a tirarlo todo ahora por la borda!"
En estos casos da lo mismo que exista una versión superior de la misma funcionalidad y que ahora está incorporada a cada runtime estándar de Java que sale, por ejemplo, o que una versión mejor se pueda descargar de forma gratuita de la fundación Apache, ¡da igual! Este software es "el nuestro".

Al igual que a los desarrolladores que llevan a cabo la refactorización puede resultarles difícil descartar un código en favor de un enfoque mejor, a las empresas les puede costar incluso más desechar su propio software. Incluso en situaciones en las que el mantenimiento continuo del monstruo obsoleto se convierte en una soga atada al cuello de la empresa.
Si bien desde fuera esta actitud parece irrazonable, se acepta muy a menudo simplemente como la forma en que las cosas se hacen en algunas organizaciones, escudándose en conceptos aleatorios inventados como la "cultura empresarial", argumento que se esgrime cuando ya no hay un planteamiento objetivo ni razonable detrás. Se podría traducir como "porque así lo quiere el jefe y punto, que es el que paga los sueldos".
También se da el caso, y cada vez más en este sector hiperactivo, de desarrolladores y empresas de mentalidad abierta que aún no son conscientes de que ya existe en el mercado un software que es justo lo que necesitan. La mayoría de los proyectos de código abierto carecen de publicidad o no se comunican bien, y quizás un programador se ha puesto a buscar y no encuentra lo que necesita, pensando que esa solución no existe y decide programarla de cero. En verdad esto no es síndrome NIA, sino falta de información. Cada vez ocurre menos, pero sigue pasando.
¿Por qué se ha propagado tanto este síndrome NIA en la industria del desarrollo de software?
Existe una creencia generalizada en Silicon Valley (la cuna y el germen de todo esto), y en el mundo tecnológico en general, de que las empresas deben "comer su propio pienso" (del inglés "eat your own dog food"), que es sólo una manera de decir que una empresa debe utilizar sus propios productos de software.
Si bien esto tiene sentido hasta un punto -no debes vender algo a los clientes que no es apto para tu propio uso-, el concepto NIA es similar, pero lleva esta línea de pensamiento al extremo. En este sentido, el término se utiliza generalmente de forma negativa y se refiere a alguien cuyas habilidades de toma de decisiones se ponen en entredicho debido a este sesgo.
Si no hago páginas web, por mucho software ERP que desarrolle, quizás es mejor subcontratar su desarrollo y mantenimiento, por poner un ejemplo.
Las explicaciones (y las emociones) detrás del síndrome NIA comprenden:
- No valorar el trabajo de otros (orgullo, en una connotación negativa)
- Miedo de no entender el trabajo de otros (falta de confianza)
- Evitar o no estar dispuesto a participar en una "guerra por el territorio" (cobardía o evitar conflictos)
- Miedo a las estrategias de un competidor, por ejemplo, una acción agresiva al intentar comprar un proveedor creando un mercado cautivo (miedo a la competencia)
- Temor a futuros problemas de suministro (miedo a la incertidumbre)
- Convencimiento de que será beneficioso el hecho de "reinventar la rueda", debido a la obtención de una cuota de mercado más controlada (avaricia)
- Celos que los productos existentes, el conocimiento, la investigación o el servicio que se ofrece no fueron creados primero por la propia empresa (vanidad y celos)
- La creencia de que las soluciones desarrolladas internamente serán siempre superiores (orgullo, en una connotación positiva)
- Rechazo de la creencia de que "el cliente es lo primero" (egoísmo)
¿Cuáles son los síntomas del síndrome "no inventado aquí"?
El principal síntoma del NIA es un ansia irrefrenable de querer re-inventar la rueda. Los síntomas secundarios, sin embargo, incluyen grandes cantidades de tiempo y dinero desperdiciado, junto con el correspondiente coste de oportunidad irrecuperable. Los desarrolladores que están ocupados picando piedra para darles una forma redonda, no están disponibles para otras funciones tales como la implementación de mejoras de seguridad, funcionalidades extra que podrían estar bien, documentación, etc... Este coste de oportunidad por sí solo suele alcanzar cantidades significativas, pero rara vez se tiene en cuenta.
El síndrome del "No Inventado Aquí" se encuentra a menudo en organizaciones y empresas donde no existe experiencia con el desarrollo orientado a componentes, y en aquellas donde la reutilización de código no se practica regularmente. Una vez que los mandos de la empresa y los jefes de proyectos entienden plenamente los beneficios de la reutilización y de los componentes, el mal del NIA es más fácil de erradicar. En este estadio, la tendencia se revierte y lo primero que se hace por defecto es buscar una solución existente, y sólo se crea a regañadientes algo internamente una vez convencidos completamente de que no existe ninguna solución fuera de la empresa que pueda ser reutilizada o ser adaptada fácilmente.
¿Cómo curar el síndrome "no inventado aquí"?
Para curarse plenamente de esta enfermedad uno debe:
- Reconocer que el NIA existe y estar atentos a los rechazos irracionales;
- Evaluar qué impacto tienen el NIA en los esfuerzos de innovación que tienes abiertos (es decir, ¿cuántas oportunidades has perdido?);
- Crear incentivos explícitos para superar el síndrome NIA (es decir, los programas recompensa para los desarrolladores);
- Involucrar a personas y organizaciones externas en las fases de estrategia y evaluación para recibir nuevas perspectivas de tus proyectos (es decir, ¿no tienes un colega de profesión que te pueda dar una segunda opinión independiente?).
Si eres capaz de seguir estos pasos, el síndrome del "No Inventado Aquí" pasará a mejor vida y tu proceso de toma de decisiones mejorará a la hora de enfocar tus proyectos de desarrollo.
Una recomendación final
Hay situaciones en cualquier proyecto de desarrollo donde es totalmente recomendable hacer un software, o cualquiera de sus componentes, de cero y a medida. Solo si ya existe una solución mejor "de fuera", o que puede cumplir perfectamente con su cometido, debemos optar por ella. Si no cumple con todos los requisitos o tu idea es mucho mejor, no estamos ante el síndrome del NIA, estamos ante una situación donde existe una necesidad legítima para crear un software nuevo.
Se puede dar en casos en los que la solución que tenemos que implementar es muy crítica, o cuando está basada en técnicas de software propietario donde es mejor hacerlo uno mismo, o cuando simplemente lo que tú necesitas y tienes en mente es OBJETIVAMENTE mejor de lo que ya hay. Aquí en estos casos no estamos ante el síndrome del no inventado aquí.
Y en tu empresa ¿se da mucho este síndrome? ¿Lo reconoces en tu forma de actuar? Deja tus comentarios abajo.